Selection Models
selmodel.RdFunction to fit selection models.
selmodel(x, ...)
# S3 method for class 'rma.uni'
selmodel(x, type, alternative="greater", prec, subset, delta,
steps, decreasing=FALSE, verbose=FALSE, digits, control, ...)Arguments
- x
an object of class
"rma.uni".- type
character string to specify the type of selection model. Possible options are
"beta","halfnorm","negexp","logistic","power","negexppow","stepfun","trunc", and"truncest". Can be abbreviated.- alternative
character string to specify the sidedness of the hypothesis when testing the effect size estimates. Possible options are
"greater"(the default),"less", or"two.sided". Can be abbreviated.- prec
optional character string to specify the measure of precision (only relevant for selection models that can incorporate this into the selection function). Possible options are
"sei","vi","ninv", or"sqrtninv".- subset
optional (logical or numeric) vector to specify the subset of studies to which the selection function applies.
- delta
optional numeric vector (of the same length as the number of selection model parameters) to fix the corresponding \(\delta\) value(s). A \(\delta\) value can be fixed by setting the corresponding element of this argument to the desired value. A \(\delta\) value will be estimated if the corresponding element is set equal to
NA.- steps
numeric vector of one or more values that can or must be specified for certain selection functions.
- decreasing
logical to specify whether the \(\delta\) values in a step function selection model must be a monotonically decreasing function of the p-values (the default is
FALSE). Only relevant whentype="stepfun".- verbose
logical to specify whether output should be generated on the progress of the model fitting (the default is
FALSE). Can also be an integer. Values > 1 generate more verbose output. See ‘Note’.- digits
optional integer to specify the number of decimal places to which the printed results should be rounded. If unspecified, the default is to take the value from the object.
- control
optional list of control values for the estimation algorithm. See ‘Note’.
- ...
other arguments.
Details
Selection models are a general class of models that attempt to model the process by which the studies included in a meta-analysis may have been influenced by some form of publication bias. If a particular selection model is an adequate approximation for the underlying selection process, then the model provides estimates of the parameters of interest (e.g., the average true effect and the amount of heterogeneity in the true effects) that are ‘corrected’ for this selection process (i.e., they are estimates of the parameters in the population of studies before any selection has taken place). The present function fits a variety of such selection models. To do so, one should pass an object fitted with the rma.uni function to the first argument. The model that will then be fitted is of the same form as the original model combined with the specific selection model chosen (see below for possible options). For example, if the original model was a random-effects model, then a random-effects selection model will be fitted. Similarly, if the original model included moderators, then they will also be accounted for in the selection model fitted. Model fitting is done via maximum likelihood (ML) estimation over the fixed- and random-effects parameters (e.g., \(\mu\) and \(\tau^2\) in a random-effects model) and the selection model parameters.
Argument type determines the specific type of selection model that should be fitted. Many selection models are based on the idea that selection may haven taken place based on the p-values of the studies. In particular, let \(y_i\) and \(v_i\) denote the effect size estimate and the corresponding sampling variance of the \(i\text{th}\) study. Then \(z_i = y_i / \sqrt{v_i}\) is the (Wald-type) test statistic for testing the null hypothesis \(\text{H}_0{:}\; \theta_i = 0\) and \(p_i = 1 - \Phi(z_i)\) (if alternative="greater"), \(p_i = \Phi(z_i)\) (if alternative="less"), or \(p_i = 2(1 - \Phi(|z_i|))\) (if alternative="two.sided") the corresponding (one- or two-sided) p-value, where \(\Phi()\) denotes the cumulative distribution function of a standard normal distribution. Finally, let \(w(p_i)\) denote some function that specifies the relative likelihood of selection given the p-value of a study.
If \(w(p_i) \gt w(p_{i'})\) when \(p_i \lt p_{i'}\) (i.e., \(w(p_i)\) is larger for smaller p-values), then alternative="greater" implies selection in favor of increasingly significant positive effects, alternative="less" implies selection in favor of increasingly significant negative effects, and alternative="two.sided" implies selection in favor of increasingly significant effects regardless of their direction.
Beta Selection Model
When type="beta", the function can be used to fit the ‘beta selection model’ by Citkowicz and Vevea (2017). For this model, the selection function is given by \[w(p_i) = p_i^{\delta_1 - 1} \times (1 - p_i)^{\delta_2 - 1}\] where \(\delta_1 \gt 0\) and \(\delta_2 \gt 0\). The null hypothesis \(\text{H}_0{:}\; \delta_1 = \delta_2 = 1\) represents the case where there is no selection according to the model. The figure below illustrates with some examples how the relative likelihood of selection can depend on the p-value for various combinations of \(\delta_1\) and \(\delta_2\). Note that the model allows for a non-monotonic selection function.
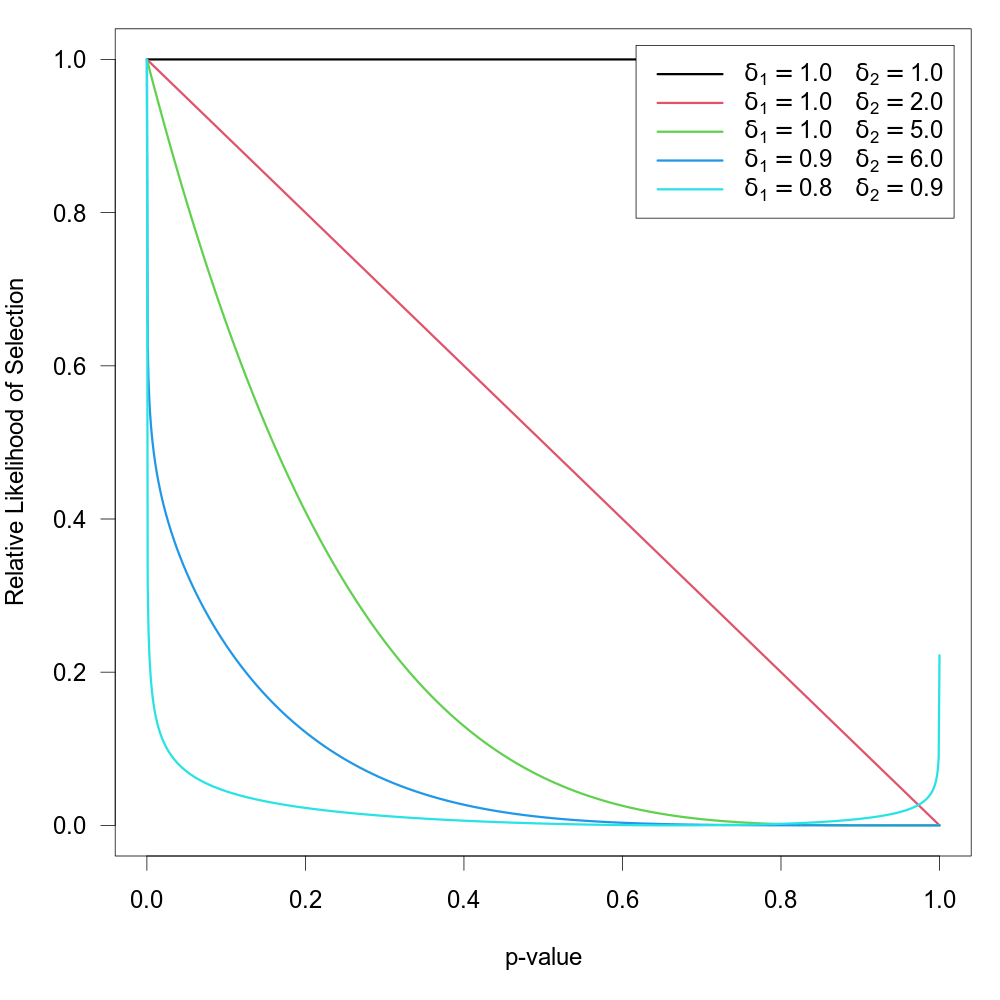
As suggested by Pustejovsky (2024), the model can be modified by truncating p-values smaller or larger than certain thresholds. The modified selection function is then given by \[w(p_i) = \tilde{p}_i^{\delta_1 - 1} \times (1 - \tilde{p}_i)^{\delta_2 - 1}\] where \(\tilde{p}_i = \text{min}(\text{max}(\alpha_1, p_i), \alpha_2)\). To fit such a selection model, one should specify the two \(\alpha\) values (with \(0 \lt \alpha \lt 1\)) via the steps argument.
Half-Normal, Negative-Exponential, Logistic, and Power Selection Models
Preston et al. (2004) suggested the first three of the following selection functions:
| name | type | selection function | ||
| half-normal | "halfnorm" | \(w(p_i) = \exp(-\delta \times p_i^2)\) | ||
| negative-exponential | "negexp" | \(w(p_i) = \exp(-\delta \times p_i)\) | ||
| logistic | "logistic" | \(w(p_i) = 2 \times \exp(-\delta \times p_i) / (1 + \exp(-\delta \times p_i))\) | ||
| power | "power" | \(w(p_i) = (1-p_i)^\delta\) |
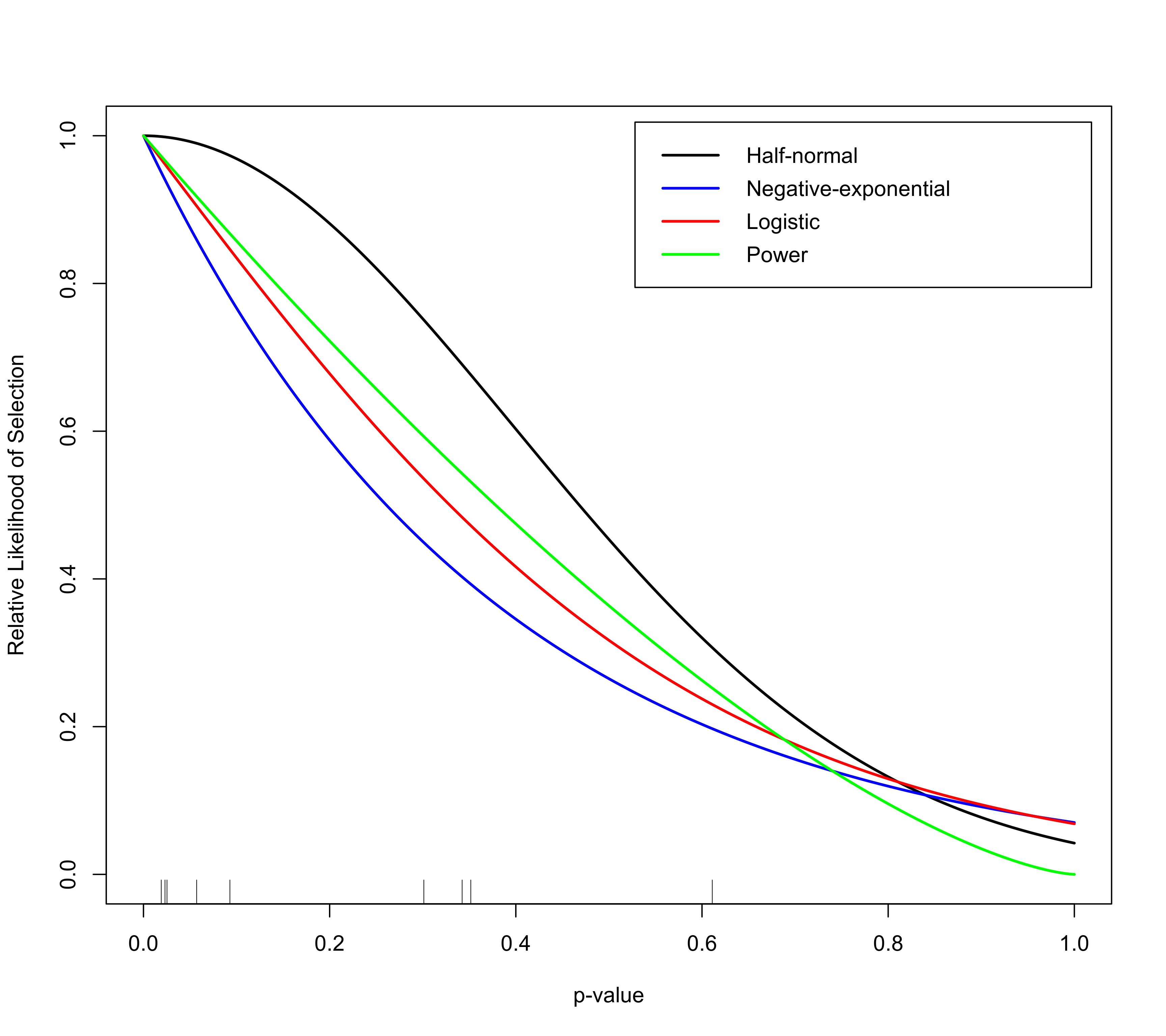
The power selection model is added here as it has similar properties as the models suggested by Preston et al. (2004). For all models, assume \(\delta \ge 0\), so that all functions imply a monotonically decreasing relationship between the p-value and the selection probability. For all functions, \(\text{H}_0{:}\; \delta = 0\) implies no selection. The figure below shows the relative likelihood of selection as a function of the p-value for \(\delta = 0\) and for the various selection functions when \(\delta = 6\).
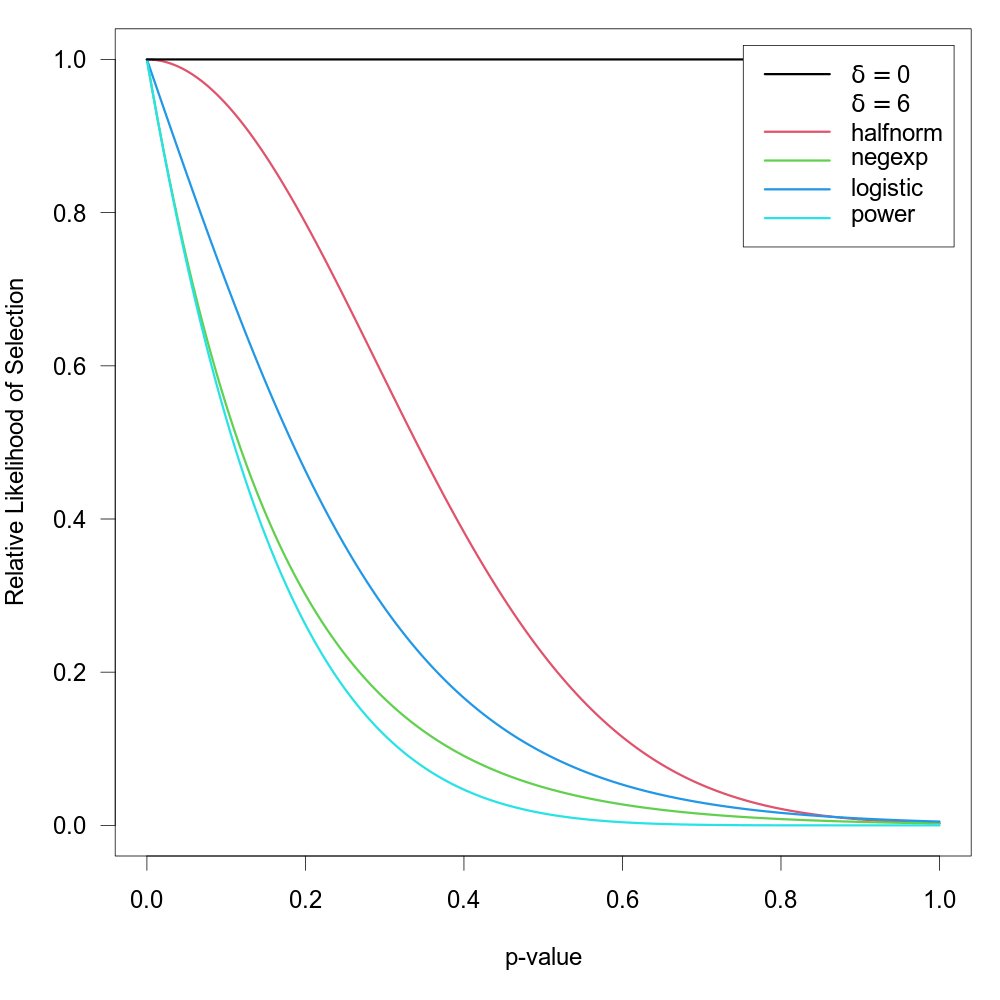
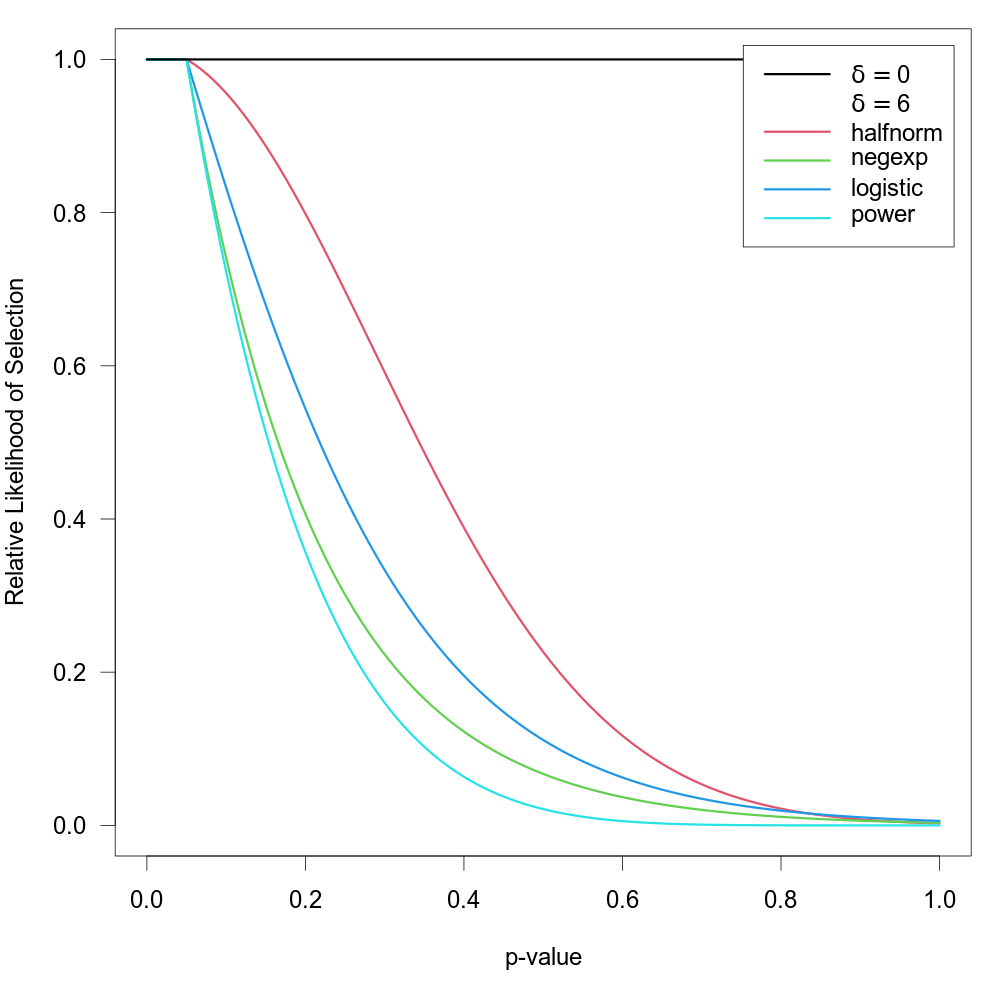
Here, these functions are extended to allow for the possibility that \(w(p_i) = 1\) for p-values below a certain significance threshold denoted by \(\alpha\) (e.g., to model the case that the relative likelihood of selection is equally high for all significant studies but decreases monotonically for p-values above the significance threshold). To fit such a selection model, one should specify the \(\alpha\) value (with \(0 \lt \alpha \lt 1\)) via the steps argument. There should be at least one observed p-value below and one observed p-value above the chosen threshold to fit these models. The selection functions are then given by \(\text{min}(1, w(p_i) / w(\alpha))\). The figure below shows some examples of the relative likelihood of selection when steps=0.05.
Preston et al. (2004) also suggested selection functions where the relatively likelihood of selection not only depends on the p-value, but also the precision (e.g., standard error) of the estimate (if two studies have similar p-values, it may be plausible to assume that the larger / more precise study has a higher probability of selection). These selection functions (plus the corresponding power function) are given by:
| name | type | selection function | ||
| half-normal | "halfnorm" | \(w(p_i) = \exp(-\delta \times \mathrm{prec}_i \times p_i^2)\) | ||
| negative-exponential | "negexp" | \(w(p_i) = \exp(-\delta \times \mathrm{prec}_i \times p_i)\) | ||
| logistic | "logistic" | \(w(p_i) = 2 \times \exp(-\delta \times \mathrm{prec}_i \times p_i) / (1 + \exp(-\delta \times \mathrm{prec}_i \times p_i))\) | ||
| power | "power" | \(w(p_i) = (1-p_i)^{\delta \times \mathrm{prec}_i}\) |
where \(\mathrm{prec}_i = \sqrt{v_i}\) (i.e., the standard error of the \(i\text{th}\) study) according to Preston et al. (2004). Here, this idea is generalized to allow the user to specify the specific measure of precision to use (via the prec argument). Possible options are:
prec="sei"for the standard errors,prec="vi"for the sampling variances,prec="ninv"for the inverse of the sample sizes,prec="sqrtninv"for the inverse square root of the sample sizes.
Using some function of the sample sizes as a measure of precision is only possible when information about the sample sizes is actually stored within the object passed to the selmodel function. See ‘Note’.
Note that \(\mathrm{prec}_i\) is really a measure of imprecision (with higher values corresponding to lower precision). Also, regardless of the specific measure chosen, the values are actually rescaled with \(\mathrm{prec}_i = \mathrm{prec}_i / \max(\mathrm{prec}_i)\) inside of the function, such that \(\mathrm{prec}_i = 1\) for the least precise study and \(\mathrm{prec}_i \lt 1\) for the remaining studies (the rescaling does not actually change the fit of the model, it only helps to improve the stability of model fitting algorithm). The figure below shows some examples of the relative likelihood of selection using these selection functions for two different precision values (note that lower values of \(\mathrm{prec}\) lead to a higher likelihood of selection).
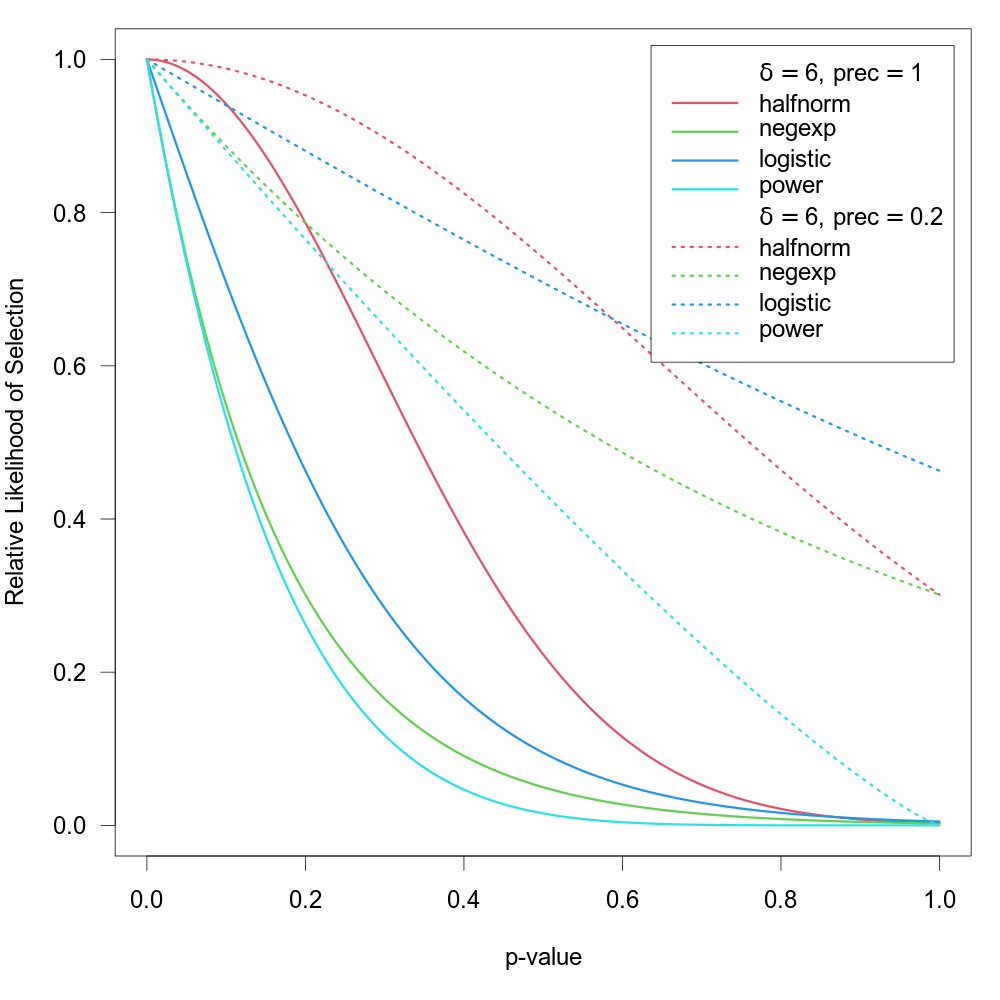
One can also use the steps argument as described above in combination with these selection functions (studies with p-values below the chosen threshold then have \(w(p_i) = 1\) regardless of their exact p-value or precision).
Negative Exponential Power Selection Model
As an extension of the half-normal and negative-exponential models, one can also choose type="negexppow" for a ‘negative exponential power selection model’. The selection function for this model is given by \[w(p_i) = \exp(-\delta_1 \times p_i^{1/\delta_2})\] where \(\delta_1 \ge 0\) and \(\delta_2 \ge 0\) (see Begg & Mazumdar, 1994, although here a different parameterization is used, such that increasing \(\delta_2\) leads to more severe selection). The figure below shows some examples of this selection function when holding \(\delta_1\) constant while increasing \(\delta_2\).
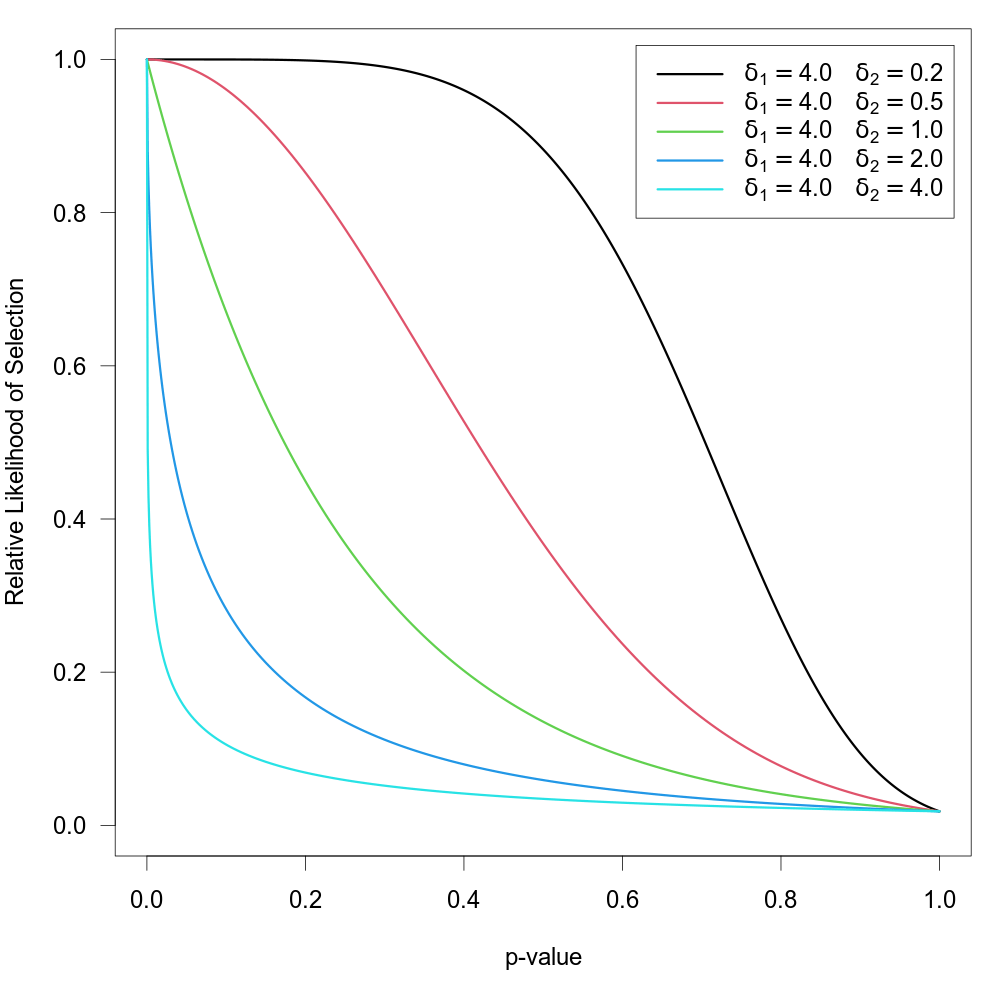
This model affords greater flexibility in the shape of the selection function, but requires the estimation of the additional power parameter (the half-normal and negative-exponential models are therefore special cases when fixing \(\delta_2\) to 0.5 or 1, respectively). \(\text{H}_0{:}\; \delta_1 = 0\) again implies no selection, but so does \(\text{H}_0{:}\; \delta_2 = 0\).
One can again use the steps argument to specify a single significance threshold, \(\alpha\), so that \(w(p_i) = 1\) for p-values below this threshold and otherwise \(w(p_i)\) follows the selection function as given above. One can also use the prec argument to specify a measure of precision in combination with this model, which leads to the selection function \[w(p_i) = \exp(-\delta_1 \times \mathrm{prec}_i \times p_i^{1/\delta_2})\] and hence is the logical extension of the negative exponential power selection model that also incorporates some measure of precision into the selection process.
Step Function Selection Models
When type="stepfun", the function can be used to fit ‘step function models’ as described by Iyengar and Greenhouse (1988), Hedges (1992), Vevea and Hedges (1995), Vevea and Woods (2005), and others. For these models, one must specify one or multiple values via the steps argument, which define intervals in which the relative likelihood of selection is constant. Let \[\alpha_1 \lt \alpha_2 \lt \ldots \lt \alpha_c\] denote these cutpoints sorted in increasing order, with the constraint that \(\alpha_c = 1\) (if the highest value specified via steps is not 1, the function will automatically add this cutpoint), and define \(\alpha_0 = 0\). The selection function is then given by \(w(p_i) = \delta_j\) for \(\alpha_{j-1} \lt p_i \le \alpha_j\) where \(\delta_j \ge 0\). To make the model identifiable, we set \(\delta_1 = 1\). The \(\delta_j\) values therefore denote the likelihood of selection in the various intervals relative to the interval for p-values between 0 and \(\alpha_1\). Hence, the null hypothesis \(\text{H}_0{:}\; \delta_j = 1\) for \(j = 1, \ldots, c\) implies no selection.
For example, if steps=c(0.05, 0.10, 0.50, 1), then \(\delta_2\) is the likelihood of selection for p-values between 0.05 and 0.10, \(\delta_3\) is the likelihood of selection for p-values between 0.10 and 0.50, and \(\delta_4\) is the likelihood of selection for p-values between 0.50 and 1 relative to the likelihood of selection for p-values between 0 and 0.05. The figure below shows the corresponding selection function for some arbitrarily chosen \(\delta_j\) values.
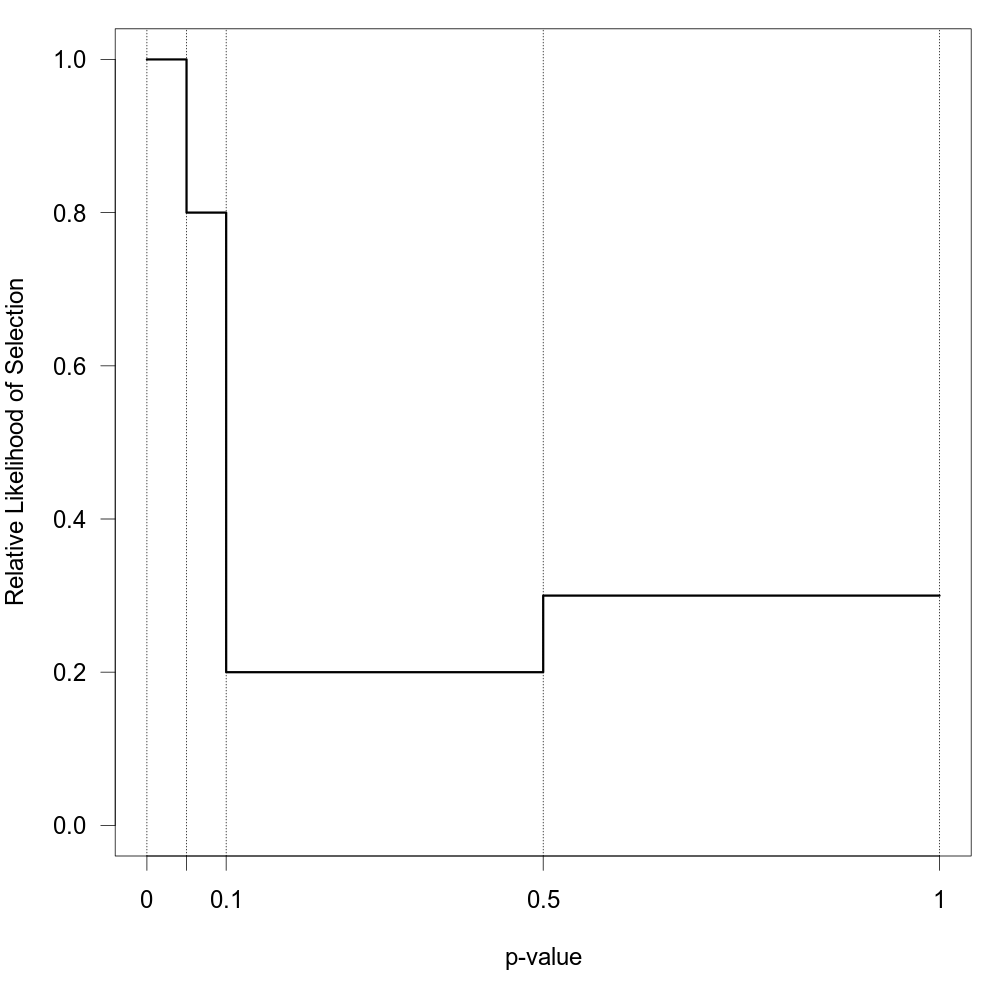
There should be at least one observed p-value within each interval to fit this model. If there are no p-values between \(\alpha_0 = 0\) and \(\alpha_1\) (i.e., within the first interval for which \(\delta_1 = 1\)), then estimates of \(\delta_2, \ldots, \delta_c\) will try to drift to infinity. If there are no p-values between \(\alpha_{j-1}\) and \(\alpha_j\) for \(j = 2, \ldots, c\), then \(\delta_j\) will try to drift to zero. In either case, results should be treated with great caution. A common practice is then to collapse and/or adjust the intervals until all intervals contain at least one study. By setting ptable=TRUE, the function simply returns the p-value table and does not attempt any model fitting.
Note that when alternative="greater" or alternative="less" (i.e., when we assume that the relative likelihood of selection is not only related to the p-values of the studies, but also the directionality of the effects), then it would usually make sense to divide conventional levels of significance (e.g., 0.05) by 2 before passing these values to the steps argument. For example, if we think that studies were selected for positive effects that are significant at two-tailed \(\alpha = 0.05\), then we should use alternative="greater" in combination with steps=c(0.025, 1).
When specifying a single cutpoint in the context of a random-effects model (typically steps=c(0.025, 1) with either alternative="greater" or alternative="less"), this model is sometimes called the ‘three-parameter selection model’ (3PSM), corresponding to the parameters \(\mu\), \(\tau^2\), and \(\delta_2\) (e.g., Carter et al., 2019; McShane et al., 2016; Pustejovsky & Rodgers, 2019). The same idea but in the context of an equal-effects model was also described by Iyengar and Greenhouse (1988).
Note that \(\delta_j\) (for \(j = 2, \ldots, c\)) can be larger than 1 (implying a greater likelihood of selection for p-values in the corresponding interval relative to the first interval). With control=list(delta.max=1), one can enforce that the likelihood of selection for p-values above the first cutpoint can never be greater than the likelihood of selection for p-values below it. This constraint should be used with caution, as it may force \(\delta_j\) estimates to fall on the boundary of the parameter space. Alternatively, one can set decreasing=TRUE, in which case the \(\delta_j\) values must be a monotonically decreasing function of the p-values (which also forces \(\delta_j \le 1\)). This feature should be considered experimental.
One of the challenges when fitting this model with many cutpoints is the large number of parameters that need to be estimated (which is especially problematic when the number of studies is small). An alternative approach suggested by Vevea and Woods (2005) is to fix the \(\delta_j\) values to some a priori chosen values instead of estimating them. One can then conduct a sensitivity analysis by examining the results (e.g., the estimates of \(\mu\) and \(\tau^2\) in a random-effects model) for a variety of different sets of \(\delta_j\) values (reflecting more or less severe forms of selection). This can be done by specifying the \(\delta_j\) values via the delta argument. Table 1 in Vevea and Woods (2005) provides some illustrative examples of moderate and severe selection functions for one- and two-tailed selection. The code below creates a data frame that contains these functions.
tab <- data.frame(
steps = c(0.005, 0.01, 0.05, 0.10, 0.25, 0.35, 0.50, 0.65, 0.75, 0.90, 0.95, 0.99, 0.995, 1),
delta.mod.1 = c(1, 0.99, 0.95, 0.80, 0.75, 0.65, 0.60, 0.55, 0.50, 0.50, 0.50, 0.50, 0.50, 0.50),
delta.sev.1 = c(1, 0.99, 0.90, 0.75, 0.60, 0.50, 0.40, 0.35, 0.30, 0.25, 0.10, 0.10, 0.10, 0.10),
delta.mod.2 = c(1, 0.99, 0.95, 0.90, 0.80, 0.75, 0.60, 0.60, 0.75, 0.80, 0.90, 0.95, 0.99, 1.00),
delta.sev.2 = c(1, 0.99, 0.90, 0.75, 0.60, 0.50, 0.25, 0.25, 0.50, 0.60, 0.75, 0.90, 0.99, 1.00))The figure below shows the corresponding selection functions.
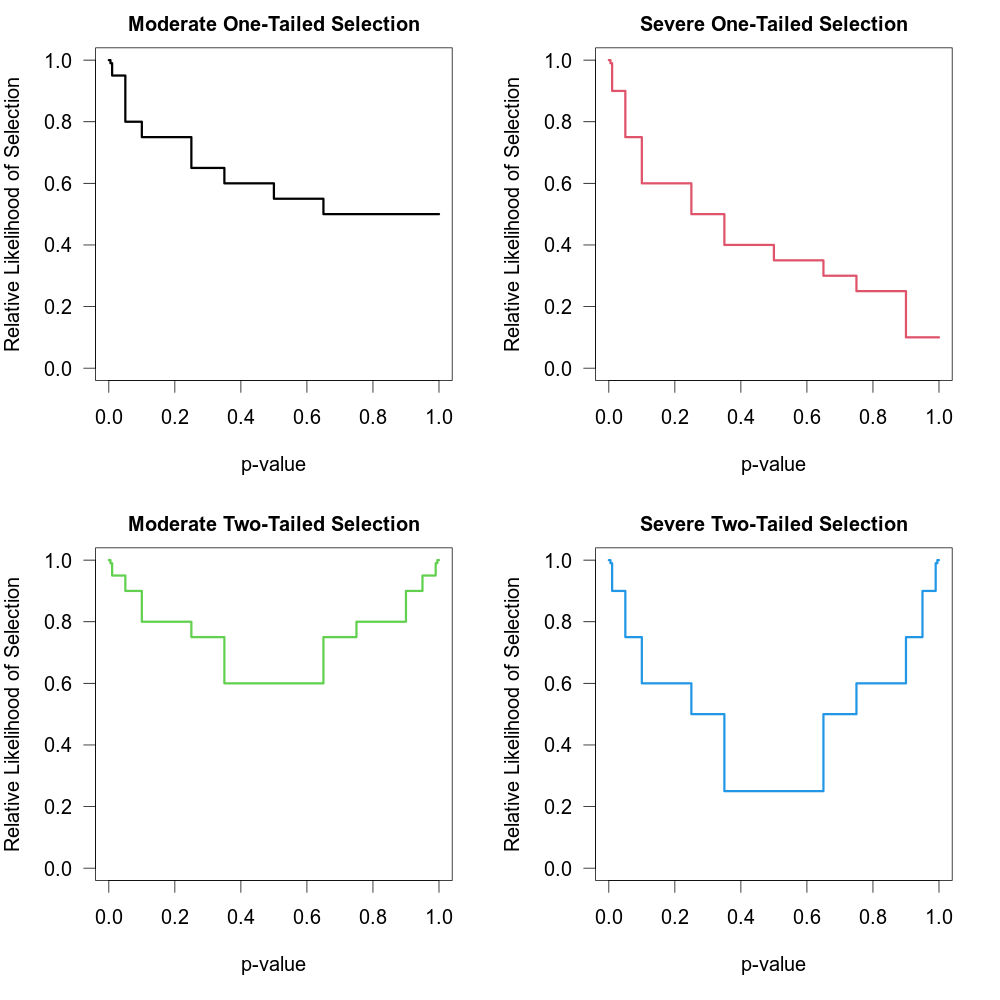
These four functions are “merely examples and should not be regarded as canonical” (Vevea & Woods, 2005).
Truncated Distribution Selection Model
When type="trunc", the model assumes that the relative likelihood of selection depends not on the p-value but on the value of the effect size estimate of a study. Let \(y_c\) denote a single cutpoint (which can be specified via argument steps and which is assumed to be 0 when unspecified). Let \[w(y_i) = \left\{ \begin{matrix} \; 1 & \text{if} \; y_i \gt y_c \\ \; \delta_1 & \text{if} \; y_i \le y_c \\ \end{matrix} \right.\] denote the selection function when alternative="greater" and \[w(y_i) = \left\{ \begin{matrix} \; 1 & \text{if} \; y_i \lt y_c \\ \; \delta_1 & \text{if} \; y_i \ge y_c \\ \end{matrix} \right.\] when alternative="less" (note that alternative="two.sided" is not an option for this type of selection model). Therefore, when alternative="greater", \(\delta_1\) denotes the likelihood of selection for effect size estimates that fall below the chosen cutpoint relative to those that fall above it (and vice-versa when alternative="less"). Hence, the null hypothesis \(\text{H}_0{:}\; \delta_1 = 1\) implies no selection.
In principle, it is also possible to obtain a maximum likelihood estimate of the cutpoint. For this, one can set type="truncest", in which case the selection function is given by \[w(y_i) = \left\{ \begin{matrix} \; 1 & \text{if} \; y_i \gt \delta_2 \\ \; \delta_1 & \text{if} \; y_i \le \delta_2 \\ \end{matrix} \right.\] when alternative="greater" and analogously when alternative="less". Therefore, instead of specifying the cutpoint via the steps argument, it is estimated via \(\delta_2\). Note that estimating both \(\delta_1\) and \(\delta_2\) simultaneously is typically very difficult (the likelihood surface is often quite rugged with multiple local optima) and will require a large number of studies. The implementation of this selection function should be considered experimental.
Models similar to those described above were proposed by Rust et al. (1990) and Formann (2008), but made various simplifying assumptions (e.g., Formann assumed \(\delta_1 = 0\)) and did not account for the heteroscedastic nature of the sampling variances of the effect size estimates, nor did they allow for heterogeneity in the true effects or the influence of moderators.
Subsets of Studies Affected and Unaffected by Publication Bias
In some meta-analyses, some of the studies are known (or are assumed) to be free of publication bias (e.g., preregistered studies). In this case, the selection function should only apply to a subset of the studies (e.g., the non-registered studies). Using the subset argument, one can specify to which subset of studies the selection function should apply (note though that all studies are still included in the model fitting). The argument can either be a logical or a numeric vector, but note that what is specified is applied to the set of data originally passed to the rma.uni function, so a logical vector must be of the same length as the original dataset (and if the data argument was used in the original model fit, then any variables specified in creating a logical vector will be searched for within this data frame first). Any subsetting and removal of studies with missing values is automatically applied to the variables specified via these arguments.
Value
An object of class c("rma.uni","rma"). The object is a list containing the same components as a regular c("rma.uni","rma") object, but the parameter estimates are based on the selection model. Most importantly, the following elements are modified based on the selection model:
- beta
estimated coefficients of the model.
- se
standard errors of the coefficients.
- zval
test statistics of the coefficients.
- pval
corresponding p-values.
- ci.lb
lower bound of the confidence intervals for the coefficients.
- ci.ub
upper bound of the confidence intervals for the coefficients.
- vb
variance-covariance matrix of the estimated coefficients.
- tau2
estimated amount of (residual) heterogeneity. Always
0whenmethod="EE".- se.tau2
standard error of the estimated amount of (residual) heterogeneity.
In addition, the object contains the following additional elements:
- delta
estimated selection model parameter(s).
- se.delta
corresponding standard error(s).
- zval.delta
corresponding test statistic(s).
- pval.delta
corresponding p-value(s).
- ci.lb.delta
lower bound of the confidence intervals for the parameter(s).
- ci.ub.delta
upper bound of the confidence intervals for the parameter(s).
- LRT
test statistic of the likelihood ratio test for the selection model parameter(s).
- LRTdf
degrees of freedom for the likelihood ratio test.
- LRTp
p-value for the likelihood ratio test.
- LRT.tau2
test statistic of the likelihood ratio test for testing \(\text{H}_0{:}\; \tau^2 = 0\) (
NAwhen fitting an equal-effects model).- LRTp.tau2
p-value for the likelihood ratio test.
- ptable
frequency table for the observed p-values falling into the intervals defined by the
stepsargument (NAwhenstepsis not specified).- ...
some additional elements/values.
Methods
The results of the fitted model are formatted and printed with the print function. The estimated selection function can be drawn with plot.
The profile function can be used to obtain a plot of the log-likelihood as a function of \(\tau^2\) and/or the selection model parameter(s) of the model. Corresponding confidence intervals can be obtained with the confint function.
Note
Model fitting is done via numerical optimization over the model parameters. By default, optim with method "BFGS" is used for the optimization. One can also chose a different optimizer from optim via the control argument (e.g., control=list(optimizer="Nelder-Mead")). Besides one of the methods from optim, one can also choose the quasi-Newton algorithm in nlminb, one of the optimizers from the minqa package (i.e., uobyqa, newuoa, or bobyqa), one of the (derivative-free) algorithms from the nloptr package, the Newton-type algorithm implemented in nlm, the various algorithms implemented in the dfoptim package (hjk for the Hooke-Jeeves, nmk for the Nelder-Mead, and mads for the Mesh Adaptive Direct Searches algorithm), the quasi-Newton type optimizers ucminf and lbfgsb3c and the subspace-searching simplex algorithm subplex from the packages of the same name, the Barzilai-Borwein gradient decent method implemented in BBoptim, the Rcgmin and Rvmmin optimizers, or the parallelized version of the L-BFGS-B algorithm implemented in optimParallel from the package of the same name.
The optimizer name must be given as a character string (i.e., in quotes). Additional control parameters can be specified via the control argument (e.g., control=list(maxit=1000, reltol=1e-8)). For nloptr, the default is to use the BOBYQA implementation from that package with a relative convergence criterion of 1e-8 on the function value (i.e., log-likelihood), but this can be changed via the algorithm and ftop_rel arguments (e.g., control=list(optimizer="nloptr", algorithm="NLOPT_LN_SBPLX", ftol_rel=1e-6)). For optimParallel, the control argument ncpus can be used to specify the number of cores to use for the parallelization (e.g., control=list(optimizer="optimParallel", ncpus=2)).
All selection models (except for type="stepfun", type="trunc", and type="truncest") require repeated evaluations of an integral, which is done via adaptive quadrature as implemented in the integrate function. One can adjust the arguments of the integrate function via control element intCtrl, which is a list of named arguments (e.g., control = list(intCtrl = list(rel.tol=1e-4, subdivisions=100))).
The starting values for the fixed effects, the \(\tau^2\) value (only relevant in random/mixed-effects selection models), and the \(\delta\) parameter(s) are chosen automatically by the function, but one can also set the starting values manually via the control argument by specifying a vector of the appropriate length for beta.init, a single value for tau2.init, and a vector of the appropriate length for delta.init.
By default, the \(\delta\) parameter(s) are constrained to a certain range, which improves the stability of the optimization algorithm. For all models, the maximum is set to 100 and the minimum to 0 (except for type="beta", where the minimum for both parameters is 1e-5, and when type="stepfun" with decreasing=TRUE, in which case the maximum is set to 1). These defaults can be changed via the control argument by specifying a scalar or a vector of the appropriate length for delta.min and/or delta.max. For example, control=list(delta.max=Inf) lifts the upper bound. Note that when a parameter estimate drifts close to its imposed bound, a warning will be issued.
A difficulty with fitting the beta selection model (i.e., type="beta") is the behavior of \(w(p_i)\) when \(p_i = 0\) or \(p_i = 1\). When \(\delta_1 \lt 1\) or \(\delta_2 \lt 1\), then this leads to selection weights equal to infinity, which causes problems when computing the likelihood function. Following Citkowicz and Vevea (2017), this problem can be avoided by censoring p-values too close to 0 or 1. The specific censoring point can be set via the pval.min element of the control argument. The default for this selection model is control=list(pval.min=1e-5). A similar issue arises for the power selection model (i.e., type="power") when \(p_i = 1\). Again, pval.min=1e-5 is used to circumvent this issue. For all other selection models, the default is pval.min=0.
The variance-covariance matrix corresponding to the estimates of the fixed effects, the \(\tau^2\) value (only relevant in random/mixed-effects selection models), and the \(\delta\) parameter(s) is obtained by inverting the Hessian, which is numerically approximated using the hessian function from the numDeriv package. This may fail, leading to NA values for the standard errors and hence test statistics, p-values, and confidence interval bounds. One can set control argument hessianCtrl to a list of named arguments to be passed on to the method.args argument of the hessian function (the default is control=list(hessianCtrl=list(r=6))). One can also set control=list(hesspack="pracma") or control=list(hesspack="calculus") in which case the pracma::hessian or calculus::hessian functions from the respective packages are used instead for approximating the Hessian. When \(\tau^2\) is estimated to be smaller than either \(10^{-4}\) or \(\min(v_1, \ldots, v_k)/10\) (where \(v_i\) denotes the sampling variances of the \(i\text{th}\) study), then \(\tau^2\) is effectively treated as zero for computing the standard errors (which helps to avoid numerical problems in approximating the Hessian). This cutoff can be adjusted via the tau2tol control argument (e.g., control=list(tau2tol=0) to switch off this behavior). Similarly, for type="beta" and type="stepfun", \(\delta\) estimates below \(10^{-4}\) are treated as effectively zero for computing the standard errors. In this case, the corresponding standard errors are NA. This cutoff can be adjusted via the deltatol control argument (e.g., control=list(deltatol=0) to switch off this behavior).
Information on the progress of the optimization algorithm can be obtained by setting verbose=TRUE (this won't work when using parallelization). One can also set verbose to an integer (verbose=2 yields even more information and verbose=3 also show the progress visually by drawing the selection function as the optimization proceeds).
For selection functions where the prec argument is relevant, using a function of the sample sizes as the measure of precision (i.e., prec="ninv" or prec="sqrtninv") is only possible when information about the sample sizes is actually stored within the object passed to the selmodel function. That should automatically be the case when the effect size estimates were computed with the escalc function or when the estimates were computed within the model fitting function. On the other hand, this will not be the case when rma.uni was used together with the yi and vi arguments and the yi and vi values were not computed with escalc. In that case, it is still possible to pass information about the sample sizes to the rma.uni function (e.g., use rma.uni(yi, vi, ni=ni, data=dat), where data frame dat includes a variable called ni with the sample sizes).
Finally, the automatic rescaling of the chosen precision measure can be switched off by setting scaleprec=FALSE.
References
Begg, C. B., & Mazumdar, M. (1994). Operating characteristics of a rank correlation test for publication bias. Biometrics, 50(4), 1088–1101. https://doi.org/10.2307/2533446
Carter, E. C., Schönbrodt, F. D., Gervais, W. M., & Hilgard, J. (2019). Correcting for bias in psychology: A comparison of meta-analytic methods. Advances in Methods and Practices in Psychological Science, 2(2), 115–144. https://doi.org/10.1177/2515245919847196
Citkowicz, M., & Vevea, J. L. (2017). A parsimonious weight function for modeling publication bias. Psychological Methods, 22(1), 28–41. https://doi.org/10.1037/met0000119
Formann, A. K. (2008). Estimating the proportion of studies missing for meta-analysis due to publication bias. Contemporary Clinical Trials, 29(5), 732–739. https://doi.org/10.1016/j.cct.2008.05.004
Hedges, L. V. (1992). Modeling publication selection effects in meta-analysis. Statistical Science, 7(2), 246–255. https://doi.org/10.1214/ss/1177011364
Iyengar, S., & Greenhouse, J. B. (1988). Selection models and the file drawer problem. Statistical Science, 3(1), 109–117. https://doi.org/10.1214/ss/1177013012
McShane, B. B., Bockenholt, U., & Hansen, K. T. (2016). Adjusting for publication bias in meta-analysis: An evaluation of selection methods and some cautionary notes. Perspectives on Psychological Science, 11(5), 730–749. https://doi.org/10.1177/1745691616662243
Preston, C., Ashby, D., & Smyth, R. (2004). Adjusting for publication bias: Modelling the selection process. Journal of Evaluation in Clinical Practice, 10(2), 313–322. https://doi.org/10.1111/j.1365-2753.2003.00457.x
Pustejovsky, J. E., & Rodgers, M. A. (2019). Testing for funnel plot asymmetry of standardized mean differences. Research Synthesis Methods, 10(1), 57–71. https://doi.org/10.1002/jrsm.1332
Pustejovsky, J. E. (2024). Beta-density selection models for meta-analysis. https://jepusto.com/posts/beta-density-selection-models/
Rust, R. T., Lehmann, D. R. & Farley, J. U. (1990). Estimating publication bias in meta-analysis. Journal of Marketing Research, 27(2), 220–226. https://doi.org/10.1177/002224379002700209
Vevea, J. L., & Hedges, L. V. (1995). A general linear model for estimating effect size in the presence of publication bias. Psychometrika, 60(3), 419–435. https://doi.org/10.1007/BF02294384
Vevea, J. L., & Woods, C. M. (2005). Publication bias in research synthesis: Sensitivity analysis using a priori weight functions. Psychological Methods, 10(4), 428–443. https://doi.org/10.1037/1082-989X.10.4.428
See also
rma.uni for the function to fit models which can be extended with selection models.
Examples
############################################################################
### example from Citkowicz and Vevea (2017) for beta selection model
# copy data into 'dat' and examine data
dat <- dat.baskerville2012
dat
#> author year score design alloconc blind itt fumonths retention country outcomes duration
#> 1 Kottke et al. 1992 6 cct 0 1 1 19 83.0 US 2 18
#> 2 McBride et al. 2000 6 rct 0 0 0 18 100.0 US 4 12
#> 3 Stange et al. 2000 6 rct 0 0 0 24 NA US 35 12
#> 4 Lobo et al. 2004 6 rct 1 0 0 21 57.0 NL 16 21
#> 5 Roetzhiem et al. 2005 6 crct 0 1 0 24 100.0 US 3 24
#> 6 Hogg et al. 2008 6 cct 0 0 1 6 87.0 Can 26 12
#> 7 Aspy et al. 2008 6 cct 0 1 0 18 89.0 US 4 18
#> 8 Jaen et al. 2010 6 rct 0 1 0 26 86.0 US 11 26
#> 9 Cockburn et al. 1992 7 rct 0 0 0 3 79.0 Aus 2 2
#> 10 Modell et al. 1998 7 rct 0 0 0 12 100.0 UK 1 12
#> 11 Engels et al. 2006 7 rct 1 0 1 12 92.0 NL 7 5
#> 12 Aspy et al. 2008 7 rct 0 1 0 9 100.0 US 1 9
#> 13 Deitrich et al. 1992 8 rct 0 1 0 12 96.0 NL 16 21
#> 14 Lobo et al. 2002 8 rct 1 0 1 21 100.0 US 10 3
#> 15 Bryce et al. 1995 9 rct 1 1 1 12 93.3 US 4 12
#> 16 Kinsinger et al. 1998 9 rct 1 1 0 18 94.0 US 5 12
#> 17 Solberg et al. 1998 9 rct 1 0 1 22 100.0 US 10 22
#> 18 Lemelin et al. 2001 9 rct 1 1 0 18 98.0 Can 13 18
#> 19 Frijling et al. 2002 9 crct 1 1 1 21 95.0 NL 7 21
#> 20 Frijling et al. 2003 9 crct 1 1 1 21 95.0 NL 12 21
#> 21 Margolis et al. 2004 10 rct 1 1 1 30 100.0 US 4 24
#> 22 Mold et al. 2008 10 rct 1 1 1 6 100.0 US 6 6
#> 23 Hogg et al. 2008 12 rct 1 1 1 13 100.0 Can 53 12
#> pperf meetings hours tailor smd se
#> 1 5.5 30.0 1.00 1 1.01 0.52
#> 2 NA 5.0 1.00 1 0.82 0.46
#> 3 20.0 4.0 1.50 1 0.59 0.23
#> 4 5.0 15.0 1.00 1 0.44 0.18
#> 5 4.0 4.0 1.00 0 0.84 0.29
#> 6 11.0 12.0 1.50 1 0.73 0.29
#> 7 3.0 3.0 6.00 1 1.12 0.36
#> 8 6.0 4.5 6.00 1 0.04 0.37
#> 9 40.0 2.0 0.25 0 0.24 0.15
#> 10 13.0 3.0 1.00 0 0.32 0.40
#> 11 NA 5.0 1.00 1 1.04 0.32
#> 12 6.0 18.0 6.00 1 1.31 0.57
#> 13 20.0 15.0 1.00 1 0.59 0.29
#> 14 8.0 3.0 1.00 1 0.66 0.19
#> 15 12.0 1.0 15.00 0 0.62 0.31
#> 16 13.0 10.0 0.75 1 0.47 0.27
#> 17 11.0 4.0 3.00 1 1.08 0.32
#> 18 8.0 33.0 1.75 1 0.98 0.32
#> 19 20.0 15.0 1.00 0 0.26 0.18
#> 20 20.0 15.0 1.00 1 0.39 0.18
#> 21 11.0 9.0 1.00 1 0.60 0.31
#> 22 8.0 18.0 4.00 1 0.94 0.53
#> 23 14.0 9.0 0.75 1 0.11 0.27
# fit random-effects model
res <- rma(smd, se^2, data=dat, method="ML", digits=3)
res
#>
#> Random-Effects Model (k = 23; tau^2 estimator: ML)
#>
#> tau^2 (estimated amount of total heterogeneity): 0.016 (SE = 0.024)
#> tau (square root of estimated tau^2 value): 0.127
#> I^2 (total heterogeneity / total variability): 18.64%
#> H^2 (total variability / sampling variability): 1.23
#>
#> Test for Heterogeneity:
#> Q(df = 22) = 27.552, p-val = 0.191
#>
#> Model Results:
#>
#> estimate se zval pval ci.lb ci.ub
#> 0.555 0.063 8.775 <.001 0.431 0.679 ***
#>
#> ---
#> Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#>
# funnel plot
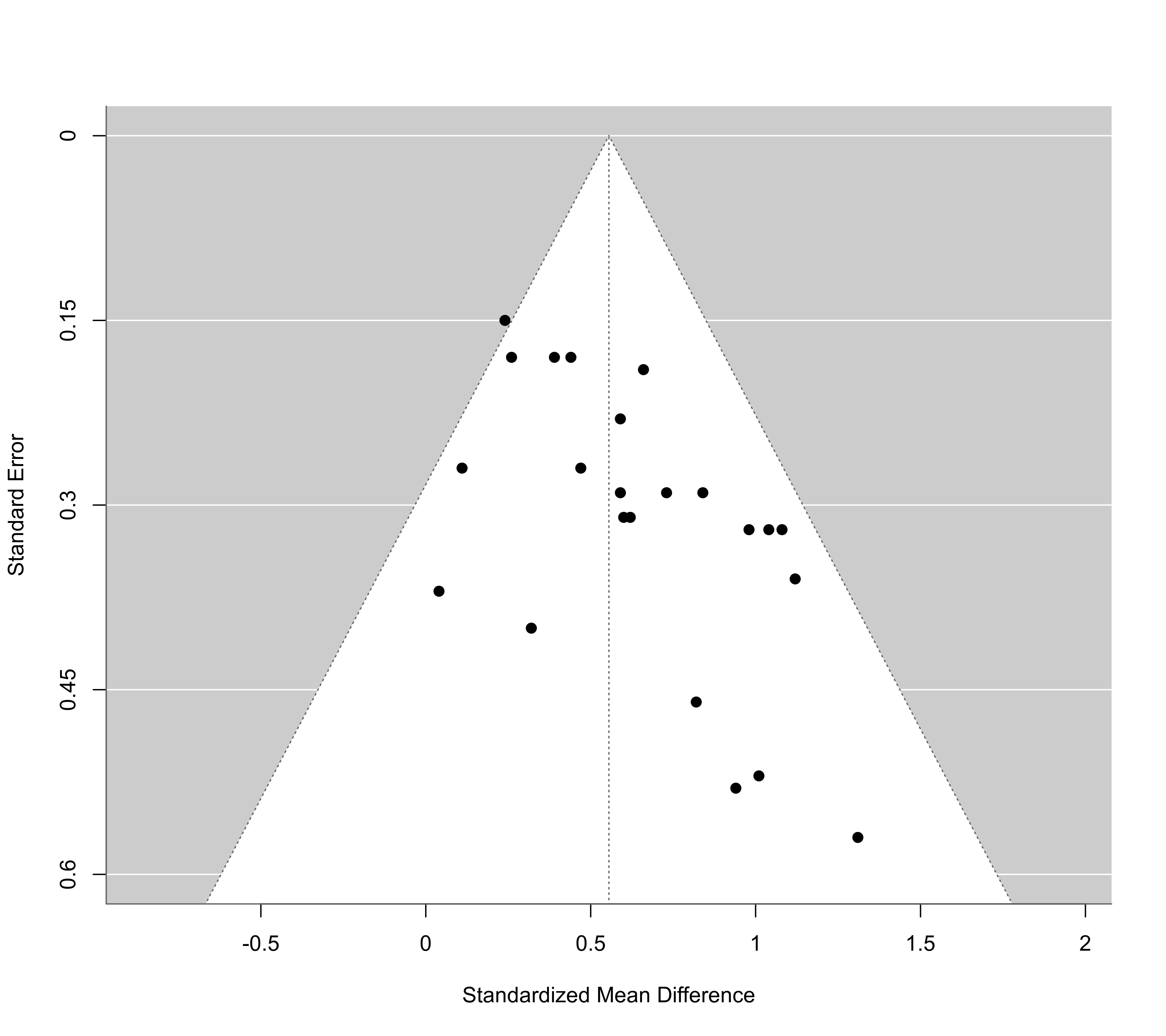
funnel(res, ylim=c(0,0.6), xlab="Standardized Mean Difference")
 # fit beta selection model
sel <- selmodel(res, type="beta")
sel
#>
#> Random-Effects Model (k = 23; tau^2 estimator: ML)
#>
#> tau^2 (estimated amount of total heterogeneity): 0.000
#> tau (square root of estimated tau^2 value): 0.002
#>
#> Test for Heterogeneity:
#> LRT(df = 1) = 0.009, p-val = 0.925
#>
#> Model Results:
#>
#> estimate se zval pval ci.lb ci.ub
#> 0.115 0.166 0.689 0.491 -0.211 0.441
#>
#> Test for Selection Model Parameters:
#> LRT(df = 2) = 7.847, p-val = 0.020
#>
#> Selection Model Results:
#>
#> estimate se zval pval ci.lb ci.ub
#> delta.1 0.473 0.235 -2.240 0.025 0.012 0.934 *
#> delta.2 4.461 2.184 1.585 0.113 0.180 8.742
#>
#> ---
#> Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#>
# plot the selection function
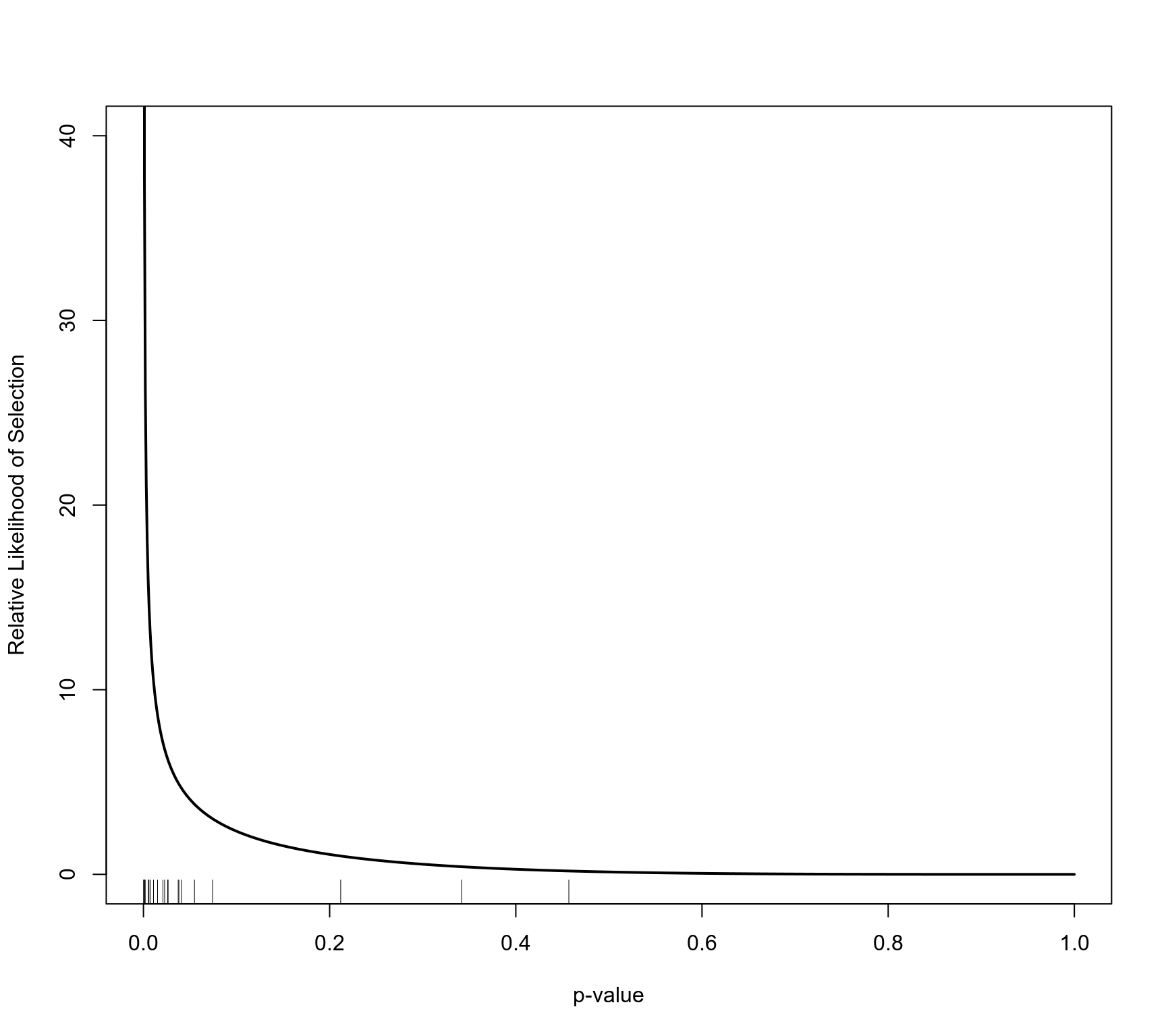
plot(sel, ylim=c(0,40))
# fit beta selection model
sel <- selmodel(res, type="beta")
sel
#>
#> Random-Effects Model (k = 23; tau^2 estimator: ML)
#>
#> tau^2 (estimated amount of total heterogeneity): 0.000
#> tau (square root of estimated tau^2 value): 0.002
#>
#> Test for Heterogeneity:
#> LRT(df = 1) = 0.009, p-val = 0.925
#>
#> Model Results:
#>
#> estimate se zval pval ci.lb ci.ub
#> 0.115 0.166 0.689 0.491 -0.211 0.441
#>
#> Test for Selection Model Parameters:
#> LRT(df = 2) = 7.847, p-val = 0.020
#>
#> Selection Model Results:
#>
#> estimate se zval pval ci.lb ci.ub
#> delta.1 0.473 0.235 -2.240 0.025 0.012 0.934 *
#> delta.2 4.461 2.184 1.585 0.113 0.180 8.742
#>
#> ---
#> Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#>
# plot the selection function
plot(sel, ylim=c(0,40))
 # only apply the selection function to studies with a quality score below 10
sel <- selmodel(res, type="beta", subset=score<10)
sel
#>
#> Random-Effects Model (k = 23; tau^2 estimator: ML)
#>
#> tau^2 (estimated amount of total heterogeneity): 0.000
#> tau (square root of estimated tau^2 value): 0.002
#>
#> Test for Heterogeneity:
#> LRT(df = 1) = 0.000, p-val = 1.000
#>
#> Model Results:
#>
#> estimate se zval pval ci.lb ci.ub
#> 0.248 0.135 1.837 0.066 -0.017 0.512 .
#>
#> Test for Selection Model Parameters:
#> LRT(df = 2) = 7.172, p-val = 0.028
#>
#> Selection Model Results (k_subset = 20):
#>
#> estimate se zval pval ci.lb ci.ub
#> delta.1 0.630 0.227 -1.633 0.102 0.186 1.074
#> delta.2 4.726 2.515 1.482 0.138 0.000 9.655
#>
#> ---
#> Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#>
# use a truncated beta selection function (need to switch optimizers to get convergence)
sel <- selmodel(res, type="beta", steps=c(0.025,0.975), control=list(optimizer="nlminb"))
#> Warning: One or more 'delta' estimates are (almost) equal to their lower or upper bound.
#> Treat results with caution (or consider adjusting 'delta.min' and/or 'delta.max').
sel
#>
#> Random-Effects Model (k = 23; tau^2 estimator: ML)
#>
#> tau^2 (estimated amount of total heterogeneity): 0.057 (SE = 0.128)
#> tau (square root of estimated tau^2 value): 0.240
#>
#> Test for Heterogeneity:
#> LRT(df = 1) = 0.880, p-val = 0.348
#>
#> Model Results:
#>
#> estimate se zval pval ci.lb ci.ub
#> 0.188 0.505 0.373 0.709 -0.801 1.178
#>
#> Test for Selection Model Parameters:
#> LRT(df = 2) = 9.541, p-val = 0.008
#>
#> Selection Model Results:
#>
#> estimate se zval pval ci.lb ci.ub
#> delta.1 0.000 0.533 -1.876 0.061 0.000 1.045 .
#> delta.2 1.741 2.175 0.341 0.733 0.000 6.005
#>
#> ---
#> Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#>
# fit mixed-effects meta-regression model with 'blind' dummy variable as moderator
res <- rma(smd, se^2, data=dat, mods = ~ blind, method="ML", digits=3)
res
#>
#> Mixed-Effects Model (k = 23; tau^2 estimator: ML)
#>
#> tau^2 (estimated amount of residual heterogeneity): 0.016 (SE = 0.024)
#> tau (square root of estimated tau^2 value): 0.128
#> I^2 (residual heterogeneity / unaccounted variability): 18.26%
#> H^2 (unaccounted variability / sampling variability): 1.22
#> R^2 (amount of heterogeneity accounted for): 0.00%
#>
#> Test for Residual Heterogeneity:
#> QE(df = 21) = 27.503, p-val = 0.155
#>
#> Test of Moderators (coefficient 2):
#> QM(df = 1) = 0.069, p-val = 0.792
#>
#> Model Results:
#>
#> estimate se zval pval ci.lb ci.ub
#> intrcpt 0.573 0.093 6.192 <.001 0.392 0.754 ***
#> blind -0.033 0.127 -0.263 0.792 -0.282 0.215
#>
#> ---
#> Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#>
# predicted average effect for studies that do not and that do use blinding
predict(res, newmods=c(0,1))
#>
#> pred se ci.lb ci.ub pi.lb pi.ub
#> 1 0.573 0.093 0.392 0.754 0.264 0.882
#> 2 0.540 0.087 0.370 0.710 0.237 0.842
#>
# fit beta selection model
sel <- selmodel(res, type="beta")
sel
#>
#> Mixed-Effects Model (k = 23; tau^2 estimator: ML)
#>
#> tau^2 (estimated amount of residual heterogeneity): 0.000
#> tau (square root of estimated tau^2 value): 0.001
#>
#> Test for Residual Heterogeneity:
#> LRT(df = 1) = 0.000, p-val = 1.000
#>
#> Test of Moderators (coefficient 2):
#> QM(df = 1) = 1.201, p-val = 0.273
#>
#> Model Results:
#>
#> estimate se zval pval ci.lb ci.ub
#> intrcpt 0.134 0.171 0.787 0.431 -0.200 0.469
#> blind -0.136 0.124 -1.096 0.273 -0.380 0.108
#>
#> Test for Selection Model Parameters:
#> LRT(df = 2) = 9.044, p-val = 0.011
#>
#> Selection Model Results:
#>
#> estimate se zval pval ci.lb ci.ub
#> delta.1 0.420 0.239 -2.425 0.015 0.000 0.889 *
#> delta.2 5.096 2.411 1.699 0.089 0.371 9.821 .
#>
#> ---
#> Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#>
predict(sel, newmods=c(0,1))
#>
#> pred se ci.lb ci.ub pi.lb pi.ub
#> 1 0.134 0.171 -0.200 0.469 -0.200 0.469
#> 2 -0.002 0.199 -0.392 0.388 -0.392 0.388
#>
############################################################################
### example from Preston et al. (2004)
# copy data into 'dat' and examine data
dat <- dat.hahn2001
dat
#> study ai n1i ci n2i
#> 1 Banhladesh 1995a 4 19 5 19
#> 2 Banhladesh 1996a 0 18 0 18
#> 3 CHOICE 2001 34 341 50 334
#> 4 Colombia 2000 7 71 16 69
#> 5 Egypt 1886a 6 45 5 44
#> 6 Egypt 1996b 1 94 8 96
#> 7 India 1984a 0 22 0 22
#> 8 India 2000b 11 88 12 82
#> 9 Mexico 1990a 2 82 7 84
#> 10 Panama 1982 0 33 0 30
#> 11 USA 1982 0 15 1 20
#> 12 WHO 1995 33 221 43 218
### meta-analysis of (log) odds rations using the Mantel-Haenszel method
res <- rma.mh(measure="OR", ai=ai, n1i=n1i, ci=ci, n2i=n2i, data=dat, digits=2, slab=study)
#> Warning: Some yi/vi values are NA.
res
#>
#> Equal-Effects Model (k = 12)
#>
#> I^2 (total heterogeneity / total variability): 0.00%
#> H^2 (total variability / sampling variability): 0.82
#>
#> Test for Heterogeneity:
#> Q(df = 8) = 6.53, p-val = 0.59
#>
#> Model Results (log scale):
#>
#> estimate se zval pval ci.lb ci.ub
#> -0.49 0.14 -3.51 <.01 -0.77 -0.22
#>
#> Model Results (OR scale):
#>
#> estimate ci.lb ci.ub
#> 0.61 0.46 0.80
#>
#> Cochran-Mantel-Haenszel Test: CMH = 12.00, df = 1, p-val < 0.01
#> Tarone's Test for Heterogeneity: X^2 = 7.58, df = 8, p-val = 0.48
#>
# calculate log odds ratios and corresponding sampling variances
dat <- escalc(measure="OR", ai=ai, n1i=n1i, ci=ci, n2i=n2i, data=dat, drop00=TRUE)
dat
#>
#> study ai n1i ci n2i yi vi
#> 1 Banhladesh 1995a 4 19 5 19 -0.2921 0.5881
#> 2 Banhladesh 1996a 0 18 0 18 NA NA
#> 3 CHOICE 2001 34 341 50 334 -0.4635 0.0562
#> 4 Colombia 2000 7 71 16 69 -1.0153 0.2399
#> 5 Egypt 1886a 6 45 5 44 0.1823 0.4179
#> 6 Egypt 1996b 1 94 8 96 -2.1347 1.1471
#> 7 India 1984a 0 22 0 22 NA NA
#> 8 India 2000b 11 88 12 82 -0.1823 0.2015
#> 9 Mexico 1990a 2 82 7 84 -1.2910 0.6683
#> 10 Panama 1982 0 33 0 30 NA NA
#> 11 USA 1982 0 15 1 20 -0.8690 2.7825
#> 12 WHO 1995 33 221 43 218 -0.3363 0.0646
#>
# fit equal-effects model
res <- rma(yi, vi, data=dat, method="EE")
#> Warning: 3 studies with NAs omitted from model fitting.
# predicted odds ratio (with 95% CI)
predict(res, transf=exp, digits=2)
#>
#> pred ci.lb ci.ub
#> 0.63 0.48 0.83
#>
# funnel plot
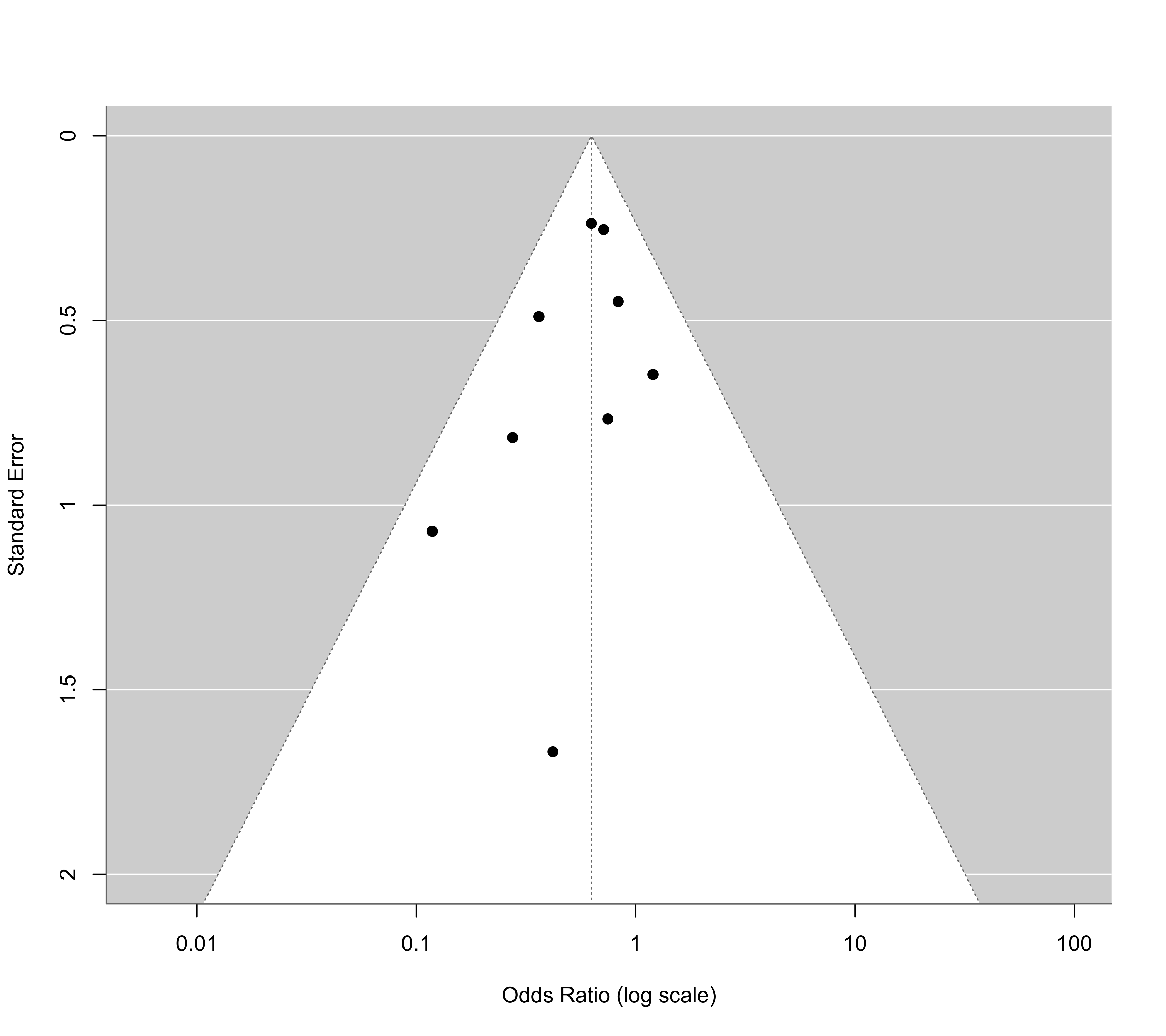
funnel(res, atransf=exp, at=log(c(0.01,0.1,1,10,100)), ylim=c(0,2))
# only apply the selection function to studies with a quality score below 10
sel <- selmodel(res, type="beta", subset=score<10)
sel
#>
#> Random-Effects Model (k = 23; tau^2 estimator: ML)
#>
#> tau^2 (estimated amount of total heterogeneity): 0.000
#> tau (square root of estimated tau^2 value): 0.002
#>
#> Test for Heterogeneity:
#> LRT(df = 1) = 0.000, p-val = 1.000
#>
#> Model Results:
#>
#> estimate se zval pval ci.lb ci.ub
#> 0.248 0.135 1.837 0.066 -0.017 0.512 .
#>
#> Test for Selection Model Parameters:
#> LRT(df = 2) = 7.172, p-val = 0.028
#>
#> Selection Model Results (k_subset = 20):
#>
#> estimate se zval pval ci.lb ci.ub
#> delta.1 0.630 0.227 -1.633 0.102 0.186 1.074
#> delta.2 4.726 2.515 1.482 0.138 0.000 9.655
#>
#> ---
#> Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#>
# use a truncated beta selection function (need to switch optimizers to get convergence)
sel <- selmodel(res, type="beta", steps=c(0.025,0.975), control=list(optimizer="nlminb"))
#> Warning: One or more 'delta' estimates are (almost) equal to their lower or upper bound.
#> Treat results with caution (or consider adjusting 'delta.min' and/or 'delta.max').
sel
#>
#> Random-Effects Model (k = 23; tau^2 estimator: ML)
#>
#> tau^2 (estimated amount of total heterogeneity): 0.057 (SE = 0.128)
#> tau (square root of estimated tau^2 value): 0.240
#>
#> Test for Heterogeneity:
#> LRT(df = 1) = 0.880, p-val = 0.348
#>
#> Model Results:
#>
#> estimate se zval pval ci.lb ci.ub
#> 0.188 0.505 0.373 0.709 -0.801 1.178
#>
#> Test for Selection Model Parameters:
#> LRT(df = 2) = 9.541, p-val = 0.008
#>
#> Selection Model Results:
#>
#> estimate se zval pval ci.lb ci.ub
#> delta.1 0.000 0.533 -1.876 0.061 0.000 1.045 .
#> delta.2 1.741 2.175 0.341 0.733 0.000 6.005
#>
#> ---
#> Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#>
# fit mixed-effects meta-regression model with 'blind' dummy variable as moderator
res <- rma(smd, se^2, data=dat, mods = ~ blind, method="ML", digits=3)
res
#>
#> Mixed-Effects Model (k = 23; tau^2 estimator: ML)
#>
#> tau^2 (estimated amount of residual heterogeneity): 0.016 (SE = 0.024)
#> tau (square root of estimated tau^2 value): 0.128
#> I^2 (residual heterogeneity / unaccounted variability): 18.26%
#> H^2 (unaccounted variability / sampling variability): 1.22
#> R^2 (amount of heterogeneity accounted for): 0.00%
#>
#> Test for Residual Heterogeneity:
#> QE(df = 21) = 27.503, p-val = 0.155
#>
#> Test of Moderators (coefficient 2):
#> QM(df = 1) = 0.069, p-val = 0.792
#>
#> Model Results:
#>
#> estimate se zval pval ci.lb ci.ub
#> intrcpt 0.573 0.093 6.192 <.001 0.392 0.754 ***
#> blind -0.033 0.127 -0.263 0.792 -0.282 0.215
#>
#> ---
#> Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#>
# predicted average effect for studies that do not and that do use blinding
predict(res, newmods=c(0,1))
#>
#> pred se ci.lb ci.ub pi.lb pi.ub
#> 1 0.573 0.093 0.392 0.754 0.264 0.882
#> 2 0.540 0.087 0.370 0.710 0.237 0.842
#>
# fit beta selection model
sel <- selmodel(res, type="beta")
sel
#>
#> Mixed-Effects Model (k = 23; tau^2 estimator: ML)
#>
#> tau^2 (estimated amount of residual heterogeneity): 0.000
#> tau (square root of estimated tau^2 value): 0.001
#>
#> Test for Residual Heterogeneity:
#> LRT(df = 1) = 0.000, p-val = 1.000
#>
#> Test of Moderators (coefficient 2):
#> QM(df = 1) = 1.201, p-val = 0.273
#>
#> Model Results:
#>
#> estimate se zval pval ci.lb ci.ub
#> intrcpt 0.134 0.171 0.787 0.431 -0.200 0.469
#> blind -0.136 0.124 -1.096 0.273 -0.380 0.108
#>
#> Test for Selection Model Parameters:
#> LRT(df = 2) = 9.044, p-val = 0.011
#>
#> Selection Model Results:
#>
#> estimate se zval pval ci.lb ci.ub
#> delta.1 0.420 0.239 -2.425 0.015 0.000 0.889 *
#> delta.2 5.096 2.411 1.699 0.089 0.371 9.821 .
#>
#> ---
#> Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#>
predict(sel, newmods=c(0,1))
#>
#> pred se ci.lb ci.ub pi.lb pi.ub
#> 1 0.134 0.171 -0.200 0.469 -0.200 0.469
#> 2 -0.002 0.199 -0.392 0.388 -0.392 0.388
#>
############################################################################
### example from Preston et al. (2004)
# copy data into 'dat' and examine data
dat <- dat.hahn2001
dat
#> study ai n1i ci n2i
#> 1 Banhladesh 1995a 4 19 5 19
#> 2 Banhladesh 1996a 0 18 0 18
#> 3 CHOICE 2001 34 341 50 334
#> 4 Colombia 2000 7 71 16 69
#> 5 Egypt 1886a 6 45 5 44
#> 6 Egypt 1996b 1 94 8 96
#> 7 India 1984a 0 22 0 22
#> 8 India 2000b 11 88 12 82
#> 9 Mexico 1990a 2 82 7 84
#> 10 Panama 1982 0 33 0 30
#> 11 USA 1982 0 15 1 20
#> 12 WHO 1995 33 221 43 218
### meta-analysis of (log) odds rations using the Mantel-Haenszel method
res <- rma.mh(measure="OR", ai=ai, n1i=n1i, ci=ci, n2i=n2i, data=dat, digits=2, slab=study)
#> Warning: Some yi/vi values are NA.
res
#>
#> Equal-Effects Model (k = 12)
#>
#> I^2 (total heterogeneity / total variability): 0.00%
#> H^2 (total variability / sampling variability): 0.82
#>
#> Test for Heterogeneity:
#> Q(df = 8) = 6.53, p-val = 0.59
#>
#> Model Results (log scale):
#>
#> estimate se zval pval ci.lb ci.ub
#> -0.49 0.14 -3.51 <.01 -0.77 -0.22
#>
#> Model Results (OR scale):
#>
#> estimate ci.lb ci.ub
#> 0.61 0.46 0.80
#>
#> Cochran-Mantel-Haenszel Test: CMH = 12.00, df = 1, p-val < 0.01
#> Tarone's Test for Heterogeneity: X^2 = 7.58, df = 8, p-val = 0.48
#>
# calculate log odds ratios and corresponding sampling variances
dat <- escalc(measure="OR", ai=ai, n1i=n1i, ci=ci, n2i=n2i, data=dat, drop00=TRUE)
dat
#>
#> study ai n1i ci n2i yi vi
#> 1 Banhladesh 1995a 4 19 5 19 -0.2921 0.5881
#> 2 Banhladesh 1996a 0 18 0 18 NA NA
#> 3 CHOICE 2001 34 341 50 334 -0.4635 0.0562
#> 4 Colombia 2000 7 71 16 69 -1.0153 0.2399
#> 5 Egypt 1886a 6 45 5 44 0.1823 0.4179
#> 6 Egypt 1996b 1 94 8 96 -2.1347 1.1471
#> 7 India 1984a 0 22 0 22 NA NA
#> 8 India 2000b 11 88 12 82 -0.1823 0.2015
#> 9 Mexico 1990a 2 82 7 84 -1.2910 0.6683
#> 10 Panama 1982 0 33 0 30 NA NA
#> 11 USA 1982 0 15 1 20 -0.8690 2.7825
#> 12 WHO 1995 33 221 43 218 -0.3363 0.0646
#>
# fit equal-effects model
res <- rma(yi, vi, data=dat, method="EE")
#> Warning: 3 studies with NAs omitted from model fitting.
# predicted odds ratio (with 95% CI)
predict(res, transf=exp, digits=2)
#>
#> pred ci.lb ci.ub
#> 0.63 0.48 0.83
#>
# funnel plot
funnel(res, atransf=exp, at=log(c(0.01,0.1,1,10,100)), ylim=c(0,2))
 # fit half-normal, negative-exponential, logistic, and power selection models
sel1 <- selmodel(res, type="halfnorm", alternative="less")
sel2 <- selmodel(res, type="negexp", alternative="less")
sel3 <- selmodel(res, type="logistic", alternative="less")
sel4 <- selmodel(res, type="power", alternative="less")
# plot the selection functions
plot(sel1)
plot(sel2, add=TRUE, col="blue")
plot(sel3, add=TRUE, col="red")
plot(sel4, add=TRUE, col="green")
# add legend
legend("topright", inset=0.02, lty="solid", lwd=2, col=c("black","blue","red","green"),
legend=c("Half-normal", "Negative-exponential", "Logistic", "Power"))
# fit half-normal, negative-exponential, logistic, and power selection models
sel1 <- selmodel(res, type="halfnorm", alternative="less")
sel2 <- selmodel(res, type="negexp", alternative="less")
sel3 <- selmodel(res, type="logistic", alternative="less")
sel4 <- selmodel(res, type="power", alternative="less")
# plot the selection functions
plot(sel1)
plot(sel2, add=TRUE, col="blue")
plot(sel3, add=TRUE, col="red")
plot(sel4, add=TRUE, col="green")
# add legend
legend("topright", inset=0.02, lty="solid", lwd=2, col=c("black","blue","red","green"),
legend=c("Half-normal", "Negative-exponential", "Logistic", "Power"))
 # show estimates of delta (and corresponding SEs)
tab <- data.frame(delta = c(sel1$delta, sel2$delta, sel3$delta, sel4$delta),
se = c(sel1$se.delta, sel2$se.delta, sel3$se.delta, sel4$se.delta))
rownames(tab) <- c("Half-normal", "Negative-exponential", "Logistic", "Power")
round(tab, 2)
#> delta se
#> Half-normal 3.16 2.99
#> Negative-exponential 2.66 2.35
#> Logistic 3.34 2.39
#> Power 1.46 1.39
# predicted odds ratios (with 95% CI)
predict(res, transf=exp, digits=2)
#>
#> pred ci.lb ci.ub
#> 0.63 0.48 0.83
#>
predict(sel1, transf=exp, digits=2)
#>
#> pred ci.lb ci.ub
#> 0.71 0.49 1.04
#>
predict(sel2, transf=exp, digits=2)
#>
#> pred ci.lb ci.ub
#> 0.76 0.48 1.20
#>
predict(sel3, transf=exp, digits=2)
#>
#> pred ci.lb ci.ub
#> 0.74 0.49 1.13
#>
predict(sel4, transf=exp, digits=2)
#>
#> pred ci.lb ci.ub
#> 0.74 0.49 1.12
#>
# fit selection models including standard error as precision measure (note: using
# scaleprec=FALSE here since Preston et al. (2004) did not use the rescaling)
sel1 <- selmodel(res, type="halfnorm", prec="sei", alternative="less", scaleprec=FALSE)
sel2 <- selmodel(res, type="negexp", prec="sei", alternative="less", scaleprec=FALSE)
sel3 <- selmodel(res, type="logistic", prec="sei", alternative="less", scaleprec=FALSE)
sel4 <- selmodel(res, type="power", prec="sei", alternative="less", scaleprec=FALSE)
# show estimates of delta (and corresponding SEs)
tab <- data.frame(delta = c(sel1$delta, sel2$delta, sel3$delta, sel4$delta),
se = c(sel1$se.delta, sel2$se.delta, sel3$se.delta, sel4$se.delta))
rownames(tab) <- c("Half-normal", "Negative-exponential", "Logistic", "Power")
round(tab, 2)
#> delta se
#> Half-normal 3.51 3.39
#> Negative-exponential 2.28 2.13
#> Logistic 3.02 2.32
#> Power 1.44 1.38
# predicted odds ratio (with 95% CI)
predict(res, transf=exp, digits=2)
#>
#> pred ci.lb ci.ub
#> 0.63 0.48 0.83
#>
predict(sel1, transf=exp, digits=2)
#>
#> pred ci.lb ci.ub
#> 0.68 0.49 0.95
#>
predict(sel2, transf=exp, digits=2)
#>
#> pred ci.lb ci.ub
#> 0.69 0.50 0.95
#>
predict(sel3, transf=exp, digits=2)
#>
#> pred ci.lb ci.ub
#> 0.68 0.50 0.93
#>
predict(sel4, transf=exp, digits=2)
#>
#> pred ci.lb ci.ub
#> 0.69 0.50 0.96
#>
############################################################################
### meta-analysis on the effect of environmental tobacco smoke on lung cancer risk
# copy data into 'dat' and examine data
dat <- dat.hackshaw1998
dat
#>
#> study author year country design cases or or.lb or.ub yi vi
#> 1 1 Garfinkel 1981 USA cohort 153 1.18 0.90 1.54 0.1655 0.0188
#> 2 2 Hirayama 1984 Japan cohort 200 1.45 1.02 2.08 0.3716 0.0330
#> 3 3 Butler 1988 USA cohort 8 2.02 0.48 8.56 0.7031 0.5402
#> 4 4 Cardenas 1997 USA cohort 150 1.20 0.80 1.60 0.1823 0.0313
#> 5 5 Chan 1982 Hong Kong case-control 84 0.75 0.43 1.30 -0.2877 0.0797
#> 6 6 Correa 1983 USA case-control 22 2.07 0.81 5.25 0.7275 0.2273
#> 7 7 Trichopolous 1983 Greece case-control 62 2.13 1.19 3.83 0.7561 0.0889
#> 8 8 Buffler 1984 USA case-control 41 0.80 0.34 1.90 -0.2231 0.1927
#> 9 9 Kabat 1984 USA case-control 24 0.79 0.25 2.45 -0.2357 0.3390
#> 10 10 Lam 1985 Hong Kong case-control 60 2.01 1.09 3.72 0.6981 0.0981
#> 11 11 Garfinkel 1985 USA case-control 134 1.23 0.81 1.87 0.2070 0.0456
#> 12 12 Wu 1985 USA case-control 29 1.20 0.50 3.30 0.1823 0.2317
#> 13 13 Akiba 1986 Japan case-control 94 1.52 0.87 2.63 0.4187 0.0796
#> 14 14 Lee 1986 UK case-control 32 1.03 0.41 2.55 0.0296 0.2174
#> 15 15 Koo 1987 Hong Kong case-control 86 1.55 0.90 2.67 0.4383 0.0770
#> 16 16 Pershagen 1987 Sweden case-control 70 1.03 0.61 1.74 0.0296 0.0715
#> 17 17 Humble 1987 USA case-control 20 2.34 0.81 6.75 0.8502 0.2926
#> 18 18 Lam 1987 Hong Kong case-control 199 1.65 1.16 2.35 0.5008 0.0324
#> 19 19 Gao 1987 China case-control 246 1.19 0.82 1.73 0.1740 0.0363
#> 20 20 Brownson 1987 USA case-control 19 1.52 0.39 5.96 0.4187 0.4839
#> 21 21 Geng 1988 China case-control 54 2.16 1.08 4.29 0.7701 0.1238
#> 22 22 Shimizu 1988 Japan case-control 90 1.08 0.64 1.82 0.0770 0.0711
#> 23 23 Inoue 1988 Japan case-control 22 2.55 0.74 8.78 0.9361 0.3982
#> 24 24 Kalandidi 1990 Greece case-control 90 1.62 0.90 2.91 0.4824 0.0896
#> 25 25 Sobue 1990 Japan case-control 144 1.06 0.74 1.52 0.0583 0.0337
#> 26 26 Wu-Williams 1990 China case-control 417 0.79 0.62 1.02 -0.2357 0.0161
#> 27 27 Liu 1991 China case-control 54 0.74 0.32 1.69 -0.3011 0.1802
#> 28 28 Jockel 1991 Germany case-control 23 2.27 0.75 6.82 0.8198 0.3171
#> 29 29 Brownson 1992 USA case-control 431 0.97 0.78 1.21 -0.0305 0.0125
#> 30 30 Stockwell 1992 USA case-control 210 1.60 0.80 3.00 0.4700 0.1137
#> 31 31 Du 1993 China case-control 75 1.19 0.66 2.13 0.1740 0.0893
#> 32 32 Liu 1993 China case-control 38 1.66 0.73 3.78 0.5068 0.1760
#> 33 33 Fontham 1994 USA case-control 651 1.26 1.04 1.54 0.2311 0.0100
#> 34 34 Kabat 1995 USA case-control 67 1.10 0.62 1.96 0.0953 0.0862
#> 35 35 Zaridze 1995 Russia case-control 162 1.66 1.12 2.45 0.5068 0.0399
#> 36 36 Sun 1996 China case-control 230 1.16 0.80 1.69 0.1484 0.0364
#> 37 37 Wang 1996 China case-control 135 1.11 0.67 1.84 0.1044 0.0664
#>
# fit random-effects model
res <- rma(yi, vi, data=dat, method="ML")
res
#>
#> Random-Effects Model (k = 37; tau^2 estimator: ML)
#>
#> tau^2 (estimated amount of total heterogeneity): 0.0204 (SE = 0.0165)
#> tau (square root of estimated tau^2 value): 0.1427
#> I^2 (total heterogeneity / total variability): 27.62%
#> H^2 (total variability / sampling variability): 1.38
#>
#> Test for Heterogeneity:
#> Q(df = 36) = 47.4979, p-val = 0.0952
#>
#> Model Results:
#>
#> estimate se zval pval ci.lb ci.ub
#> 0.2171 0.0486 4.4712 <.0001 0.1219 0.3123 ***
#>
#> ---
#> Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#>
# funnel plot
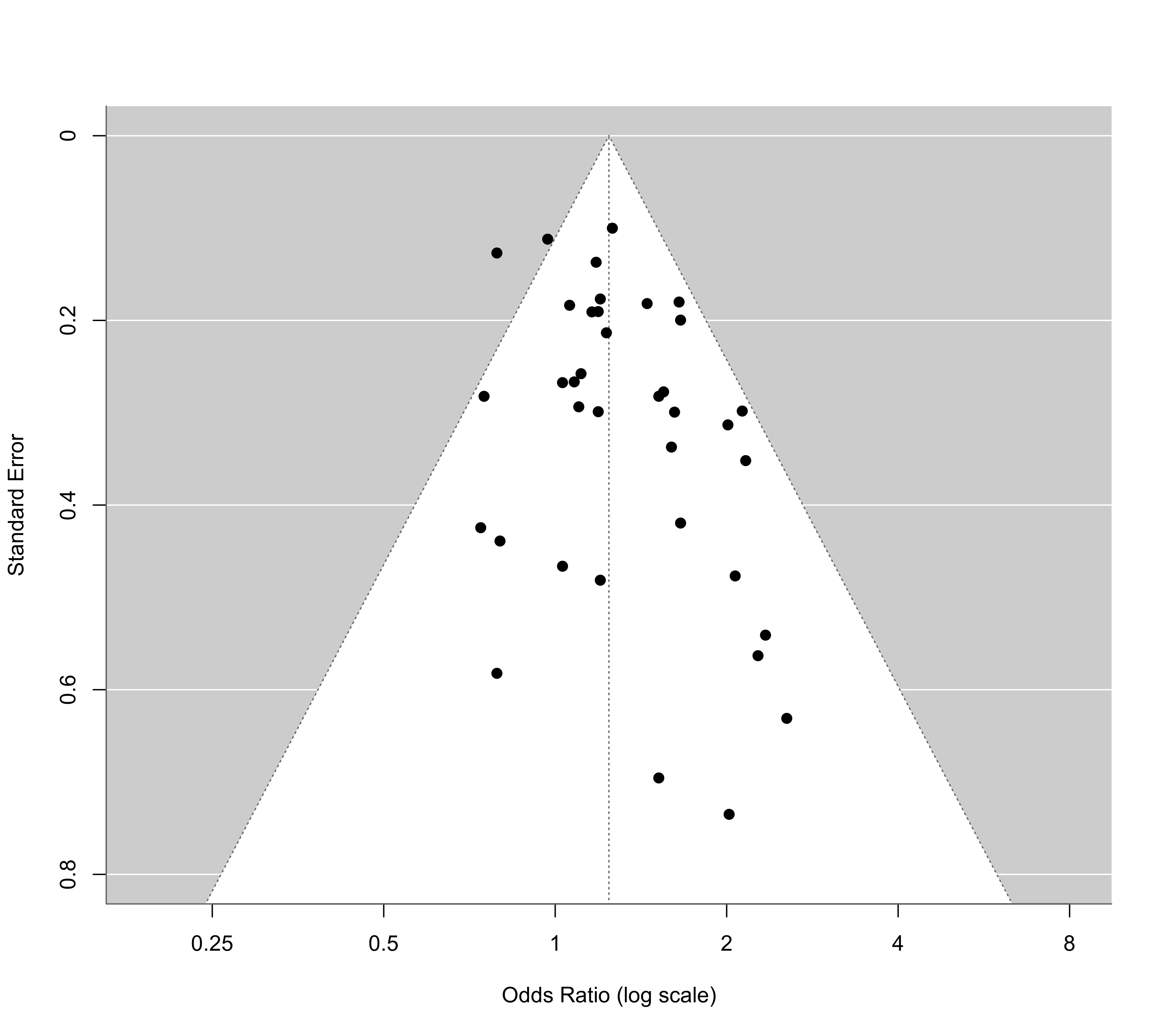
funnel(res, atransf=exp, at=log(c(0.25,0.5,1,2,4,8)), ylim=c(0,0.8))
# show estimates of delta (and corresponding SEs)
tab <- data.frame(delta = c(sel1$delta, sel2$delta, sel3$delta, sel4$delta),
se = c(sel1$se.delta, sel2$se.delta, sel3$se.delta, sel4$se.delta))
rownames(tab) <- c("Half-normal", "Negative-exponential", "Logistic", "Power")
round(tab, 2)
#> delta se
#> Half-normal 3.16 2.99
#> Negative-exponential 2.66 2.35
#> Logistic 3.34 2.39
#> Power 1.46 1.39
# predicted odds ratios (with 95% CI)
predict(res, transf=exp, digits=2)
#>
#> pred ci.lb ci.ub
#> 0.63 0.48 0.83
#>
predict(sel1, transf=exp, digits=2)
#>
#> pred ci.lb ci.ub
#> 0.71 0.49 1.04
#>
predict(sel2, transf=exp, digits=2)
#>
#> pred ci.lb ci.ub
#> 0.76 0.48 1.20
#>
predict(sel3, transf=exp, digits=2)
#>
#> pred ci.lb ci.ub
#> 0.74 0.49 1.13
#>
predict(sel4, transf=exp, digits=2)
#>
#> pred ci.lb ci.ub
#> 0.74 0.49 1.12
#>
# fit selection models including standard error as precision measure (note: using
# scaleprec=FALSE here since Preston et al. (2004) did not use the rescaling)
sel1 <- selmodel(res, type="halfnorm", prec="sei", alternative="less", scaleprec=FALSE)
sel2 <- selmodel(res, type="negexp", prec="sei", alternative="less", scaleprec=FALSE)
sel3 <- selmodel(res, type="logistic", prec="sei", alternative="less", scaleprec=FALSE)
sel4 <- selmodel(res, type="power", prec="sei", alternative="less", scaleprec=FALSE)
# show estimates of delta (and corresponding SEs)
tab <- data.frame(delta = c(sel1$delta, sel2$delta, sel3$delta, sel4$delta),
se = c(sel1$se.delta, sel2$se.delta, sel3$se.delta, sel4$se.delta))
rownames(tab) <- c("Half-normal", "Negative-exponential", "Logistic", "Power")
round(tab, 2)
#> delta se
#> Half-normal 3.51 3.39
#> Negative-exponential 2.28 2.13
#> Logistic 3.02 2.32
#> Power 1.44 1.38
# predicted odds ratio (with 95% CI)
predict(res, transf=exp, digits=2)
#>
#> pred ci.lb ci.ub
#> 0.63 0.48 0.83
#>
predict(sel1, transf=exp, digits=2)
#>
#> pred ci.lb ci.ub
#> 0.68 0.49 0.95
#>
predict(sel2, transf=exp, digits=2)
#>
#> pred ci.lb ci.ub
#> 0.69 0.50 0.95
#>
predict(sel3, transf=exp, digits=2)
#>
#> pred ci.lb ci.ub
#> 0.68 0.50 0.93
#>
predict(sel4, transf=exp, digits=2)
#>
#> pred ci.lb ci.ub
#> 0.69 0.50 0.96
#>
############################################################################
### meta-analysis on the effect of environmental tobacco smoke on lung cancer risk
# copy data into 'dat' and examine data
dat <- dat.hackshaw1998
dat
#>
#> study author year country design cases or or.lb or.ub yi vi
#> 1 1 Garfinkel 1981 USA cohort 153 1.18 0.90 1.54 0.1655 0.0188
#> 2 2 Hirayama 1984 Japan cohort 200 1.45 1.02 2.08 0.3716 0.0330
#> 3 3 Butler 1988 USA cohort 8 2.02 0.48 8.56 0.7031 0.5402
#> 4 4 Cardenas 1997 USA cohort 150 1.20 0.80 1.60 0.1823 0.0313
#> 5 5 Chan 1982 Hong Kong case-control 84 0.75 0.43 1.30 -0.2877 0.0797
#> 6 6 Correa 1983 USA case-control 22 2.07 0.81 5.25 0.7275 0.2273
#> 7 7 Trichopolous 1983 Greece case-control 62 2.13 1.19 3.83 0.7561 0.0889
#> 8 8 Buffler 1984 USA case-control 41 0.80 0.34 1.90 -0.2231 0.1927
#> 9 9 Kabat 1984 USA case-control 24 0.79 0.25 2.45 -0.2357 0.3390
#> 10 10 Lam 1985 Hong Kong case-control 60 2.01 1.09 3.72 0.6981 0.0981
#> 11 11 Garfinkel 1985 USA case-control 134 1.23 0.81 1.87 0.2070 0.0456
#> 12 12 Wu 1985 USA case-control 29 1.20 0.50 3.30 0.1823 0.2317
#> 13 13 Akiba 1986 Japan case-control 94 1.52 0.87 2.63 0.4187 0.0796
#> 14 14 Lee 1986 UK case-control 32 1.03 0.41 2.55 0.0296 0.2174
#> 15 15 Koo 1987 Hong Kong case-control 86 1.55 0.90 2.67 0.4383 0.0770
#> 16 16 Pershagen 1987 Sweden case-control 70 1.03 0.61 1.74 0.0296 0.0715
#> 17 17 Humble 1987 USA case-control 20 2.34 0.81 6.75 0.8502 0.2926
#> 18 18 Lam 1987 Hong Kong case-control 199 1.65 1.16 2.35 0.5008 0.0324
#> 19 19 Gao 1987 China case-control 246 1.19 0.82 1.73 0.1740 0.0363
#> 20 20 Brownson 1987 USA case-control 19 1.52 0.39 5.96 0.4187 0.4839
#> 21 21 Geng 1988 China case-control 54 2.16 1.08 4.29 0.7701 0.1238
#> 22 22 Shimizu 1988 Japan case-control 90 1.08 0.64 1.82 0.0770 0.0711
#> 23 23 Inoue 1988 Japan case-control 22 2.55 0.74 8.78 0.9361 0.3982
#> 24 24 Kalandidi 1990 Greece case-control 90 1.62 0.90 2.91 0.4824 0.0896
#> 25 25 Sobue 1990 Japan case-control 144 1.06 0.74 1.52 0.0583 0.0337
#> 26 26 Wu-Williams 1990 China case-control 417 0.79 0.62 1.02 -0.2357 0.0161
#> 27 27 Liu 1991 China case-control 54 0.74 0.32 1.69 -0.3011 0.1802
#> 28 28 Jockel 1991 Germany case-control 23 2.27 0.75 6.82 0.8198 0.3171
#> 29 29 Brownson 1992 USA case-control 431 0.97 0.78 1.21 -0.0305 0.0125
#> 30 30 Stockwell 1992 USA case-control 210 1.60 0.80 3.00 0.4700 0.1137
#> 31 31 Du 1993 China case-control 75 1.19 0.66 2.13 0.1740 0.0893
#> 32 32 Liu 1993 China case-control 38 1.66 0.73 3.78 0.5068 0.1760
#> 33 33 Fontham 1994 USA case-control 651 1.26 1.04 1.54 0.2311 0.0100
#> 34 34 Kabat 1995 USA case-control 67 1.10 0.62 1.96 0.0953 0.0862
#> 35 35 Zaridze 1995 Russia case-control 162 1.66 1.12 2.45 0.5068 0.0399
#> 36 36 Sun 1996 China case-control 230 1.16 0.80 1.69 0.1484 0.0364
#> 37 37 Wang 1996 China case-control 135 1.11 0.67 1.84 0.1044 0.0664
#>
# fit random-effects model
res <- rma(yi, vi, data=dat, method="ML")
res
#>
#> Random-Effects Model (k = 37; tau^2 estimator: ML)
#>
#> tau^2 (estimated amount of total heterogeneity): 0.0204 (SE = 0.0165)
#> tau (square root of estimated tau^2 value): 0.1427
#> I^2 (total heterogeneity / total variability): 27.62%
#> H^2 (total variability / sampling variability): 1.38
#>
#> Test for Heterogeneity:
#> Q(df = 36) = 47.4979, p-val = 0.0952
#>
#> Model Results:
#>
#> estimate se zval pval ci.lb ci.ub
#> 0.2171 0.0486 4.4712 <.0001 0.1219 0.3123 ***
#>
#> ---
#> Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#>
# funnel plot
funnel(res, atransf=exp, at=log(c(0.25,0.5,1,2,4,8)), ylim=c(0,0.8))
 # step function selection model
sel <- selmodel(res, type="stepfun", alternative="greater", steps=c(0.025,0.10,0.50,1))
sel
#>
#> Random-Effects Model (k = 37; tau^2 estimator: ML)
#>
#> tau^2 (estimated amount of total heterogeneity): 0.0096 (SE = 0.0128)
#> tau (square root of estimated tau^2 value): 0.0981
#>
#> Test for Heterogeneity:
#> LRT(df = 1) = 1.1374, p-val = 0.2862
#>
#> Model Results:
#>
#> estimate se zval pval ci.lb ci.ub
#> 0.0020 0.0889 0.0225 0.9821 -0.1723 0.1763
#>
#> Test for Selection Model Parameters:
#> LRT(df = 3) = 6.4020, p-val = 0.0936
#>
#> Selection Model Results:
#>
#> k estimate se zval pval ci.lb ci.ub
#> 0 < p <= 0.025 7 1.0000 --- --- --- --- ---
#> 0.025 < p <= 0.1 8 0.4946 0.3152 -1.6032 0.1089 0.0000 1.1125
#> 0.1 < p <= 0.5 16 0.2136 0.1687 -4.6612 <.0001 0.0000 0.5443 ***
#> 0.5 < p <= 1 6 0.0618 0.0689 -13.6171 <.0001 0.0000 0.1969 ***
#>
#> ---
#> Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#>
# plot the selection function
plot(sel)
# step function selection model
sel <- selmodel(res, type="stepfun", alternative="greater", steps=c(0.025,0.10,0.50,1))
sel
#>
#> Random-Effects Model (k = 37; tau^2 estimator: ML)
#>
#> tau^2 (estimated amount of total heterogeneity): 0.0096 (SE = 0.0128)
#> tau (square root of estimated tau^2 value): 0.0981
#>
#> Test for Heterogeneity:
#> LRT(df = 1) = 1.1374, p-val = 0.2862
#>
#> Model Results:
#>
#> estimate se zval pval ci.lb ci.ub
#> 0.0020 0.0889 0.0225 0.9821 -0.1723 0.1763
#>
#> Test for Selection Model Parameters:
#> LRT(df = 3) = 6.4020, p-val = 0.0936
#>
#> Selection Model Results:
#>
#> k estimate se zval pval ci.lb ci.ub
#> 0 < p <= 0.025 7 1.0000 --- --- --- --- ---
#> 0.025 < p <= 0.1 8 0.4946 0.3152 -1.6032 0.1089 0.0000 1.1125
#> 0.1 < p <= 0.5 16 0.2136 0.1687 -4.6612 <.0001 0.0000 0.5443 ***
#> 0.5 < p <= 1 6 0.0618 0.0689 -13.6171 <.0001 0.0000 0.1969 ***
#>
#> ---
#> Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#>
# plot the selection function
plot(sel)
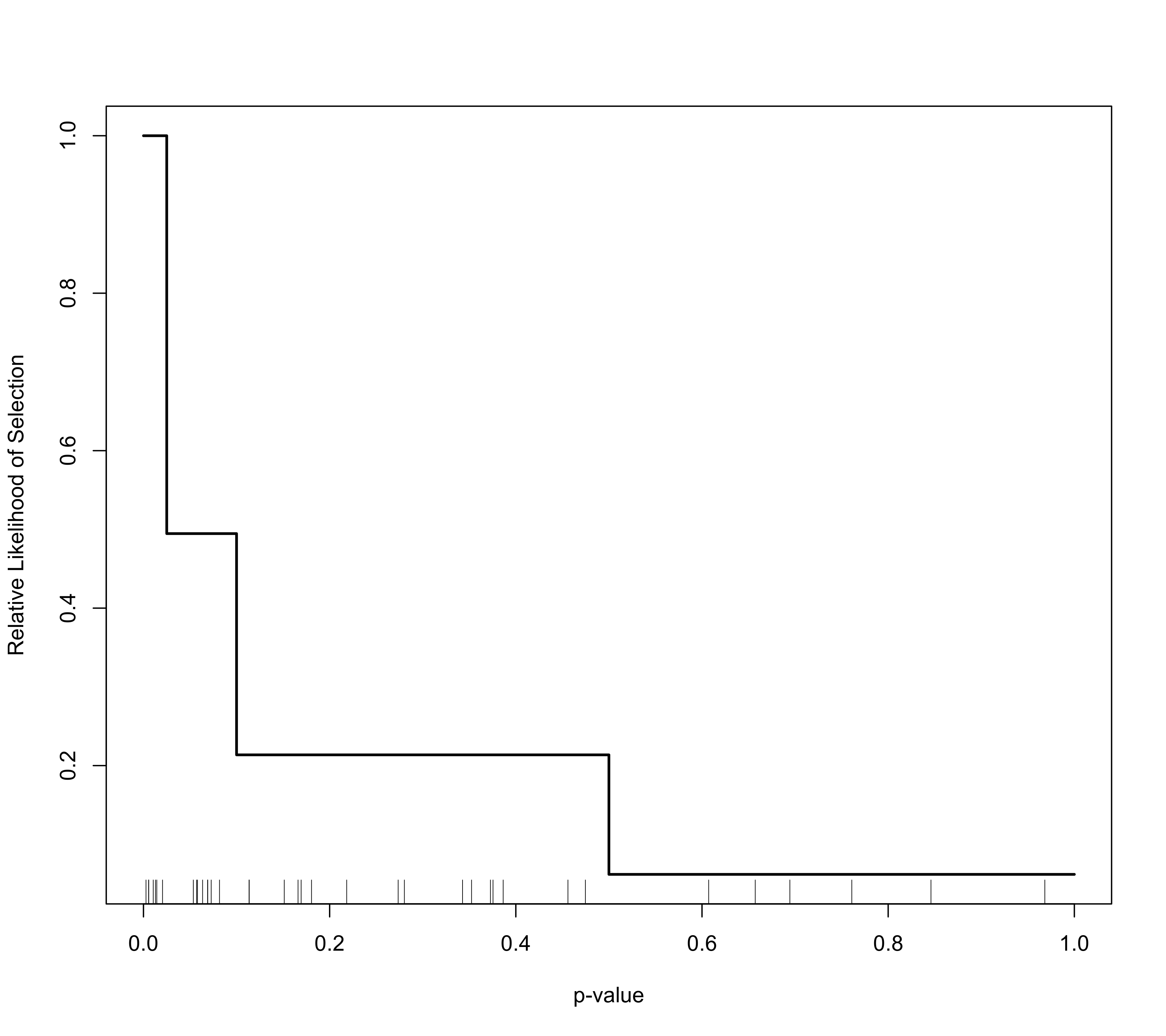 # truncated distribution selection model (with steps=0 by default)
sel <- selmodel(res, type="trunc")
sel
#>
#> Random-Effects Model (k = 37; tau^2 estimator: ML)
#>
#> tau^2 (estimated amount of total heterogeneity): 0.0268 (SE = 0.0206)
#> tau (square root of estimated tau^2 value): 0.1636
#>
#> Test for Heterogeneity:
#> LRT(df = 1) = 4.8734, p-val = 0.0273
#>
#> Model Results:
#>
#> estimate se zval pval ci.lb ci.ub
#> 0.1427 0.0741 1.9267 0.0540 -0.0025 0.2879 .
#>
#> Test for Selection Model Parameters:
#> LRT(df = 1) = 3.0545, p-val = 0.0805
#>
#> Selection Model Results:
#>
#> estimate se zval pval ci.lb ci.ub
#> 0.3818 0.2236 -2.7652 0.0057 0.0000 0.8200 **
#>
#> ---
#> Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#>
############################################################################
### meta-analysis on the effect of the color red on attractiveness ratings
# copy data into 'dat', select only results for male raters, and examine data
dat <- dat.lehmann2018
dat <- dat[dat$Gender == "Males",]
dat[c(1,6,48:49)]
#> Short_Title Preregistered yi vi
#> 2 Roberts et al., 2010 - Exp 2 Not Pre-Registered 0.40140989 0.016037663
#> 4 Gilston & Privitera, 2016 - Exp 1 - Healthy Not Pre-Registered 1.91636755 0.037967265
#> 6 Roberts et al., 2010 - Exp 1 Not Pre-Registered 0.18521296 0.005905064
#> 7 Roberts et al., 2010 - Exp 3 Not Pre-Registered -0.07521478 0.006513145
#> 9 Young, 2015 - Exp 1 - More Attractive Not Pre-Registered 0.13756419 0.004182208
#> 10 Young, 2015 - Exp 2 - More Attractive Not Pre-Registered 0.10038754 0.001196496
#> 11 Pazda et al., 2017 - Exp 1 Not Pre-Registered 0.17390851 0.002914105
#> 12 Pazda et al., 2017 - Exp 2 Pre-Registered 0.09948184 0.001749773
#> 16 Seibt & Klement, 2015 - Exp 1 Not Pre-Registered 0.19656583 0.155504946
#> 19 Costello et al., 2017 - Exp 1 Not Pre-Registered -0.12471327 0.031069900
#> 20 O'Mara et al., 2016 - Exp 2 - Long Shirt Not Pre-Registered 0.44777911 0.136466242
#> 22 Lin, 2014 - Exp 1 Not Pre-Registered 1.53467244 0.129440244
#> 23 O'Mara et al., 2016 - Exp 2 - Tank Top Not Pre-Registered -0.31843818 0.143905188
#> 24 Seibt, 2015 - Exp 1 Not Pre-Registered 0.19652340 0.046351337
#> 30 Pazda et al., 2012 - Exp 2 Not Pre-Registered 0.63094089 0.086553689
#> 31 Gueguen, 2012 - Exp 1 Not Pre-Registered 0.73851566 0.046716967
#> 32 O'Mara et al., 2016 - Exp 1 - Long Shirt Not Pre-Registered 0.46807729 0.066024574
#> 37 O'Mara et al., 2016 - Exp 1 - Tank Top Not Pre-Registered 0.09736644 0.058051891
#> 40 Pazda et al., 2014 - Exp 1 Not Pre-Registered 0.32014826 0.017393318
#> 42 Sullivan et al., 2016 - Exp 1 Not Pre-Registered 0.42424573 0.044023214
#> 43 Lehmann & Calin-Jageman, 2015 - Class Exp Not Pre-Registered -0.23427621 0.039865319
#> 46 Elliot & Niesta, 2008 - Exp 4 Not Pre-Registered 0.61911019 0.135348883
#> 48 Elliot & Niesta, 2008 - Exp 3 Not Pre-Registered 0.66521276 0.114803368
#> 53 Elliot & Niesta, 2008 - Exp 5 Not Pre-Registered 0.84272904 0.189681386
#> 55 Elliot & Niesta, 2008 - Exp 2 Not Pre-Registered 0.75415459 0.133886705
#> 57 Schwarz & Singer, 2013 - Exp 1 - Adults Rate Young Not Pre-Registered 0.19094046 0.066970485
#> 58 Williams & Neelon, 2013 - Exp 1 - All Not Pre-Registered 0.57970525 0.134586960
#> 60 Sullivan et al., 2016 - Exp 2 Not Pre-Registered 0.01713415 0.119051813
#> 62 Purdy, 2009 - Exp 1 - High Arousal Not Pre-Registered 0.30214822 0.155601799
#> 63 Elliot & Niesta, 2008 - Exp 1 Not Pre-Registered 1.08120844 0.171648364
#> 64 Bigelow et al., 2013 - Exp 1 Not Pre-Registered -0.73259462 0.533543430
#> 65 Purdy, 2009 - Exp 1 - Low Arousal Not Pre-Registered 0.01111323 0.153848529
#> 67 Stefan & Gueguen, 2013 - Exp 1 Not Pre-Registered 0.61658647 0.123646421
#> 68 Lehmann & Calin-Jageman, 2017 - Exp 2 Pre-Registered 0.09812924 0.019072274
#> 69 Peperkoorn et al., 2016 - Exp 1 - Short Term Not Pre-Registered -0.42730137 0.060166077
#> 70 Peperkoorn et al., 2016 - Exp 2 - Short Term Not Pre-Registered -0.10469267 0.058160232
#> 71 Schwarz & Singer, 2013 - Exp 1 - UGrads Rate Young Not Pre-Registered -0.15120389 0.066857188
#> 73 Kirsch, 2015 - Exp 1 - Heterosexual Not Pre-Registered 0.32006349 0.038865006
#> 74 Kirsch, 2015 - Exp 2 Not Pre-Registered 0.02798718 0.071435565
#> 75 Lehmann & Calin-Jageman, 2017 - Exp 1 Pre-Registered 0.00000000 0.138528139
#> 76 Williams & Neelon, 2013 - Exp 2 - Positive and Neutral Not Pre-Registered -0.13013126 0.077085905
#> 77 O'Mara et al., 2016 - Exp 3 - Tank Top Not Pre-Registered -0.12154628 0.037859348
#> 78 O'Mara et al., 2016 - Exp 3 - Long Shirt Not Pre-Registered -0.13650517 0.033494516
#> 79 Elliot et al., 2013 - Exp 1 Not Pre-Registered 0.64366707 0.100170325
#> 80 Wen et al., 2014 - Exp 1 - Feminine Females Not Pre-Registered 0.15882531 0.068372920
# fit random-effects model
res <- rma(yi, vi, data=dat, method="ML")
res
#>
#> Random-Effects Model (k = 45; tau^2 estimator: ML)
#>
#> tau^2 (estimated amount of total heterogeneity): 0.1334 (SE = 0.0405)
#> tau (square root of estimated tau^2 value): 0.3652
#> I^2 (total heterogeneity / total variability): 88.58%
#> H^2 (total variability / sampling variability): 8.76
#>
#> Test for Heterogeneity:
#> Q(df = 44) = 172.4651, p-val < .0001
#>
#> Model Results:
#>
#> estimate se zval pval ci.lb ci.ub
#> 0.2604 0.0665 3.9139 <.0001 0.1300 0.3908 ***
#>
#> ---
#> Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#>
# step function selection model (3PSM)
sel <- selmodel(res, type="stepfun", alternative="greater", steps=0.025)
sel
#>
#> Random-Effects Model (k = 45; tau^2 estimator: ML)
#>
#> tau^2 (estimated amount of total heterogeneity): 0.1235 (SE = 0.0417)
#> tau (square root of estimated tau^2 value): 0.3515
#>
#> Test for Heterogeneity:
#> LRT(df = 1) = 45.8737, p-val < .0001
#>
#> Model Results:
#>
#> estimate se zval pval ci.lb ci.ub
#> 0.2074 0.1001 2.0724 0.0382 0.0113 0.4036 *
#>
#> Test for Selection Model Parameters:
#> LRT(df = 1) = 0.4455, p-val = 0.5045
#>
#> Selection Model Results:
#>
#> k estimate se zval pval ci.lb ci.ub
#> 0 < p <= 0.025 16 1.0000 --- --- --- --- ---
#> 0.025 < p <= 1 29 0.6974 0.3764 -0.8039 0.4214 0.0000 1.4352
#>
#> ---
#> Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#>
# step function selection model that only applies to the non-preregistered studies
sel <- selmodel(res, type="stepfun", alternative="greater", steps=0.025,
subset=Preregistered=="Not Pre-Registered")
sel
#>
#> Random-Effects Model (k = 45; tau^2 estimator: ML)
#>
#> tau^2 (estimated amount of total heterogeneity): 0.1212 (SE = 0.0409)
#> tau (square root of estimated tau^2 value): 0.3481
#>
#> Test for Heterogeneity:
#> LRT(df = 1) = 45.2965, p-val < .0001
#>
#> Model Results:
#>
#> estimate se zval pval ci.lb ci.ub
#> 0.1992 0.0941 2.1162 0.0343 0.0147 0.3837 *
#>
#> Test for Selection Model Parameters:
#> LRT(df = 1) = 0.7203, p-val = 0.3960
#>
#> Selection Model Results (k_subset = 42):
#>
#> k estimate se zval pval ci.lb ci.ub
#> 0 < p <= 0.025 15 1.0000 --- --- --- --- ---
#> 0.025 < p <= 1 27 0.6371 0.3381 -1.0735 0.2830 0.0000 1.2997
#>
#> ---
#> Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#>
############################################################################
### validity of student ratings example from Vevea & Woods (2005)
# copy data into 'dat' and examine data
dat <- dat.cohen1981
dat[c(1,4,5)]
#> study ni ri
#> 1 Bolton et al. 1979 10 0.68
#> 2 Bryson 1974 20 0.56
#> 3 Centra 1977 13 0.23
#> 4 Centra 1977 22 0.64
#> 5 Crooks & Smock 1974 28 0.49
#> 6 Doyle & Crichton 1978 12 -0.04
#> 7 Doyle & Whitely 1974 12 0.49
#> 8 Elliott 1950 36 0.33
#> 9 Ellis & Rickard 1977 19 0.58
#> 10 Frey et al. 1975 12 0.18
#> 11 Greenwood et al. 1976 36 -0.11
#> 12 Hoffman 1978 75 0.27
#> 13 McKeachie et al. 1971 33 0.26
#> 14 Morsh et al. 1956 121 0.40
#> 15 Remmers et al. 1949 37 0.49
#> 16 Sullivan & Skanes 1974 14 0.51
#> 17 Sullivan & Skanes 1974 40 0.40
#> 18 Sullivan & Skanes 1974 16 0.34
#> 19 Sullivan & Skanes 1974 14 0.42
#> 20 Wherry 1952 20 0.16
# calculate r-to-z transformed correlations and corresponding sampling variances
dat <- escalc(measure="ZCOR", ri=ri, ni=ni, data=dat[c(1,4,5)])
dat
#>
#> study ni ri yi vi
#> 1 Bolton et al. 1979 10 0.68 0.8291 0.1429
#> 2 Bryson 1974 20 0.56 0.6328 0.0588
#> 3 Centra 1977 13 0.23 0.2342 0.1000
#> 4 Centra 1977 22 0.64 0.7582 0.0526
#> 5 Crooks & Smock 1974 28 0.49 0.5361 0.0400
#> 6 Doyle & Crichton 1978 12 -0.04 -0.0400 0.1111
#> 7 Doyle & Whitely 1974 12 0.49 0.5361 0.1111
#> 8 Elliott 1950 36 0.33 0.3428 0.0303
#> 9 Ellis & Rickard 1977 19 0.58 0.6625 0.0625
#> 10 Frey et al. 1975 12 0.18 0.1820 0.1111
#> 11 Greenwood et al. 1976 36 -0.11 -0.1104 0.0303
#> 12 Hoffman 1978 75 0.27 0.2769 0.0139
#> 13 McKeachie et al. 1971 33 0.26 0.2661 0.0333
#> 14 Morsh et al. 1956 121 0.40 0.4236 0.0085
#> 15 Remmers et al. 1949 37 0.49 0.5361 0.0294
#> 16 Sullivan & Skanes 1974 14 0.51 0.5627 0.0909
#> 17 Sullivan & Skanes 1974 40 0.40 0.4236 0.0270
#> 18 Sullivan & Skanes 1974 16 0.34 0.3541 0.0769
#> 19 Sullivan & Skanes 1974 14 0.42 0.4477 0.0909
#> 20 Wherry 1952 20 0.16 0.1614 0.0588
#>
# fit random-effects model
res <- rma(yi, vi, data=dat, method="ML", digits=3)
res
#>
#> Random-Effects Model (k = 20; tau^2 estimator: ML)
#>
#> tau^2 (estimated amount of total heterogeneity): 0.001 (SE = 0.009)
#> tau (square root of estimated tau^2 value): 0.034
#> I^2 (total heterogeneity / total variability): 2.86%
#> H^2 (total variability / sampling variability): 1.03
#>
#> Test for Heterogeneity:
#> Q(df = 19) = 20.974, p-val = 0.338
#>
#> Model Results:
#>
#> estimate se zval pval ci.lb ci.ub
#> 0.380 0.045 8.505 <.001 0.292 0.468 ***
#>
#> ---
#> Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#>
# predicted average correlation (with 95% CI)
predict(res, transf=transf.ztor)
#>
#> pred ci.lb ci.ub pi.lb pi.ub
#> 0.363 0.284 0.436 0.263 0.455
#>
# funnel plot
funnel(res, ylim=c(0,0.4))
# truncated distribution selection model (with steps=0 by default)
sel <- selmodel(res, type="trunc")
sel
#>
#> Random-Effects Model (k = 37; tau^2 estimator: ML)
#>
#> tau^2 (estimated amount of total heterogeneity): 0.0268 (SE = 0.0206)
#> tau (square root of estimated tau^2 value): 0.1636
#>
#> Test for Heterogeneity:
#> LRT(df = 1) = 4.8734, p-val = 0.0273
#>
#> Model Results:
#>
#> estimate se zval pval ci.lb ci.ub
#> 0.1427 0.0741 1.9267 0.0540 -0.0025 0.2879 .
#>
#> Test for Selection Model Parameters:
#> LRT(df = 1) = 3.0545, p-val = 0.0805
#>
#> Selection Model Results:
#>
#> estimate se zval pval ci.lb ci.ub
#> 0.3818 0.2236 -2.7652 0.0057 0.0000 0.8200 **
#>
#> ---
#> Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#>
############################################################################
### meta-analysis on the effect of the color red on attractiveness ratings
# copy data into 'dat', select only results for male raters, and examine data
dat <- dat.lehmann2018
dat <- dat[dat$Gender == "Males",]
dat[c(1,6,48:49)]
#> Short_Title Preregistered yi vi
#> 2 Roberts et al., 2010 - Exp 2 Not Pre-Registered 0.40140989 0.016037663
#> 4 Gilston & Privitera, 2016 - Exp 1 - Healthy Not Pre-Registered 1.91636755 0.037967265
#> 6 Roberts et al., 2010 - Exp 1 Not Pre-Registered 0.18521296 0.005905064
#> 7 Roberts et al., 2010 - Exp 3 Not Pre-Registered -0.07521478 0.006513145
#> 9 Young, 2015 - Exp 1 - More Attractive Not Pre-Registered 0.13756419 0.004182208
#> 10 Young, 2015 - Exp 2 - More Attractive Not Pre-Registered 0.10038754 0.001196496
#> 11 Pazda et al., 2017 - Exp 1 Not Pre-Registered 0.17390851 0.002914105
#> 12 Pazda et al., 2017 - Exp 2 Pre-Registered 0.09948184 0.001749773
#> 16 Seibt & Klement, 2015 - Exp 1 Not Pre-Registered 0.19656583 0.155504946
#> 19 Costello et al., 2017 - Exp 1 Not Pre-Registered -0.12471327 0.031069900
#> 20 O'Mara et al., 2016 - Exp 2 - Long Shirt Not Pre-Registered 0.44777911 0.136466242
#> 22 Lin, 2014 - Exp 1 Not Pre-Registered 1.53467244 0.129440244
#> 23 O'Mara et al., 2016 - Exp 2 - Tank Top Not Pre-Registered -0.31843818 0.143905188
#> 24 Seibt, 2015 - Exp 1 Not Pre-Registered 0.19652340 0.046351337
#> 30 Pazda et al., 2012 - Exp 2 Not Pre-Registered 0.63094089 0.086553689
#> 31 Gueguen, 2012 - Exp 1 Not Pre-Registered 0.73851566 0.046716967
#> 32 O'Mara et al., 2016 - Exp 1 - Long Shirt Not Pre-Registered 0.46807729 0.066024574
#> 37 O'Mara et al., 2016 - Exp 1 - Tank Top Not Pre-Registered 0.09736644 0.058051891
#> 40 Pazda et al., 2014 - Exp 1 Not Pre-Registered 0.32014826 0.017393318
#> 42 Sullivan et al., 2016 - Exp 1 Not Pre-Registered 0.42424573 0.044023214
#> 43 Lehmann & Calin-Jageman, 2015 - Class Exp Not Pre-Registered -0.23427621 0.039865319
#> 46 Elliot & Niesta, 2008 - Exp 4 Not Pre-Registered 0.61911019 0.135348883
#> 48 Elliot & Niesta, 2008 - Exp 3 Not Pre-Registered 0.66521276 0.114803368
#> 53 Elliot & Niesta, 2008 - Exp 5 Not Pre-Registered 0.84272904 0.189681386
#> 55 Elliot & Niesta, 2008 - Exp 2 Not Pre-Registered 0.75415459 0.133886705
#> 57 Schwarz & Singer, 2013 - Exp 1 - Adults Rate Young Not Pre-Registered 0.19094046 0.066970485
#> 58 Williams & Neelon, 2013 - Exp 1 - All Not Pre-Registered 0.57970525 0.134586960
#> 60 Sullivan et al., 2016 - Exp 2 Not Pre-Registered 0.01713415 0.119051813
#> 62 Purdy, 2009 - Exp 1 - High Arousal Not Pre-Registered 0.30214822 0.155601799
#> 63 Elliot & Niesta, 2008 - Exp 1 Not Pre-Registered 1.08120844 0.171648364
#> 64 Bigelow et al., 2013 - Exp 1 Not Pre-Registered -0.73259462 0.533543430
#> 65 Purdy, 2009 - Exp 1 - Low Arousal Not Pre-Registered 0.01111323 0.153848529
#> 67 Stefan & Gueguen, 2013 - Exp 1 Not Pre-Registered 0.61658647 0.123646421
#> 68 Lehmann & Calin-Jageman, 2017 - Exp 2 Pre-Registered 0.09812924 0.019072274
#> 69 Peperkoorn et al., 2016 - Exp 1 - Short Term Not Pre-Registered -0.42730137 0.060166077
#> 70 Peperkoorn et al., 2016 - Exp 2 - Short Term Not Pre-Registered -0.10469267 0.058160232
#> 71 Schwarz & Singer, 2013 - Exp 1 - UGrads Rate Young Not Pre-Registered -0.15120389 0.066857188
#> 73 Kirsch, 2015 - Exp 1 - Heterosexual Not Pre-Registered 0.32006349 0.038865006
#> 74 Kirsch, 2015 - Exp 2 Not Pre-Registered 0.02798718 0.071435565
#> 75 Lehmann & Calin-Jageman, 2017 - Exp 1 Pre-Registered 0.00000000 0.138528139
#> 76 Williams & Neelon, 2013 - Exp 2 - Positive and Neutral Not Pre-Registered -0.13013126 0.077085905
#> 77 O'Mara et al., 2016 - Exp 3 - Tank Top Not Pre-Registered -0.12154628 0.037859348
#> 78 O'Mara et al., 2016 - Exp 3 - Long Shirt Not Pre-Registered -0.13650517 0.033494516
#> 79 Elliot et al., 2013 - Exp 1 Not Pre-Registered 0.64366707 0.100170325
#> 80 Wen et al., 2014 - Exp 1 - Feminine Females Not Pre-Registered 0.15882531 0.068372920
# fit random-effects model
res <- rma(yi, vi, data=dat, method="ML")
res
#>
#> Random-Effects Model (k = 45; tau^2 estimator: ML)
#>
#> tau^2 (estimated amount of total heterogeneity): 0.1334 (SE = 0.0405)
#> tau (square root of estimated tau^2 value): 0.3652
#> I^2 (total heterogeneity / total variability): 88.58%
#> H^2 (total variability / sampling variability): 8.76
#>
#> Test for Heterogeneity:
#> Q(df = 44) = 172.4651, p-val < .0001
#>
#> Model Results:
#>
#> estimate se zval pval ci.lb ci.ub
#> 0.2604 0.0665 3.9139 <.0001 0.1300 0.3908 ***
#>
#> ---
#> Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#>
# step function selection model (3PSM)
sel <- selmodel(res, type="stepfun", alternative="greater", steps=0.025)
sel
#>
#> Random-Effects Model (k = 45; tau^2 estimator: ML)
#>
#> tau^2 (estimated amount of total heterogeneity): 0.1235 (SE = 0.0417)
#> tau (square root of estimated tau^2 value): 0.3515
#>
#> Test for Heterogeneity:
#> LRT(df = 1) = 45.8737, p-val < .0001
#>
#> Model Results:
#>
#> estimate se zval pval ci.lb ci.ub
#> 0.2074 0.1001 2.0724 0.0382 0.0113 0.4036 *
#>
#> Test for Selection Model Parameters:
#> LRT(df = 1) = 0.4455, p-val = 0.5045
#>
#> Selection Model Results:
#>
#> k estimate se zval pval ci.lb ci.ub
#> 0 < p <= 0.025 16 1.0000 --- --- --- --- ---
#> 0.025 < p <= 1 29 0.6974 0.3764 -0.8039 0.4214 0.0000 1.4352
#>
#> ---
#> Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#>
# step function selection model that only applies to the non-preregistered studies
sel <- selmodel(res, type="stepfun", alternative="greater", steps=0.025,
subset=Preregistered=="Not Pre-Registered")
sel
#>
#> Random-Effects Model (k = 45; tau^2 estimator: ML)
#>
#> tau^2 (estimated amount of total heterogeneity): 0.1212 (SE = 0.0409)
#> tau (square root of estimated tau^2 value): 0.3481
#>
#> Test for Heterogeneity:
#> LRT(df = 1) = 45.2965, p-val < .0001
#>
#> Model Results:
#>
#> estimate se zval pval ci.lb ci.ub
#> 0.1992 0.0941 2.1162 0.0343 0.0147 0.3837 *
#>
#> Test for Selection Model Parameters:
#> LRT(df = 1) = 0.7203, p-val = 0.3960
#>
#> Selection Model Results (k_subset = 42):
#>
#> k estimate se zval pval ci.lb ci.ub
#> 0 < p <= 0.025 15 1.0000 --- --- --- --- ---
#> 0.025 < p <= 1 27 0.6371 0.3381 -1.0735 0.2830 0.0000 1.2997
#>
#> ---
#> Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#>
############################################################################
### validity of student ratings example from Vevea & Woods (2005)
# copy data into 'dat' and examine data
dat <- dat.cohen1981
dat[c(1,4,5)]
#> study ni ri
#> 1 Bolton et al. 1979 10 0.68
#> 2 Bryson 1974 20 0.56
#> 3 Centra 1977 13 0.23
#> 4 Centra 1977 22 0.64
#> 5 Crooks & Smock 1974 28 0.49
#> 6 Doyle & Crichton 1978 12 -0.04
#> 7 Doyle & Whitely 1974 12 0.49
#> 8 Elliott 1950 36 0.33
#> 9 Ellis & Rickard 1977 19 0.58
#> 10 Frey et al. 1975 12 0.18
#> 11 Greenwood et al. 1976 36 -0.11
#> 12 Hoffman 1978 75 0.27
#> 13 McKeachie et al. 1971 33 0.26
#> 14 Morsh et al. 1956 121 0.40
#> 15 Remmers et al. 1949 37 0.49
#> 16 Sullivan & Skanes 1974 14 0.51
#> 17 Sullivan & Skanes 1974 40 0.40
#> 18 Sullivan & Skanes 1974 16 0.34
#> 19 Sullivan & Skanes 1974 14 0.42
#> 20 Wherry 1952 20 0.16
# calculate r-to-z transformed correlations and corresponding sampling variances
dat <- escalc(measure="ZCOR", ri=ri, ni=ni, data=dat[c(1,4,5)])
dat
#>
#> study ni ri yi vi
#> 1 Bolton et al. 1979 10 0.68 0.8291 0.1429
#> 2 Bryson 1974 20 0.56 0.6328 0.0588
#> 3 Centra 1977 13 0.23 0.2342 0.1000
#> 4 Centra 1977 22 0.64 0.7582 0.0526
#> 5 Crooks & Smock 1974 28 0.49 0.5361 0.0400
#> 6 Doyle & Crichton 1978 12 -0.04 -0.0400 0.1111
#> 7 Doyle & Whitely 1974 12 0.49 0.5361 0.1111
#> 8 Elliott 1950 36 0.33 0.3428 0.0303
#> 9 Ellis & Rickard 1977 19 0.58 0.6625 0.0625
#> 10 Frey et al. 1975 12 0.18 0.1820 0.1111
#> 11 Greenwood et al. 1976 36 -0.11 -0.1104 0.0303
#> 12 Hoffman 1978 75 0.27 0.2769 0.0139
#> 13 McKeachie et al. 1971 33 0.26 0.2661 0.0333
#> 14 Morsh et al. 1956 121 0.40 0.4236 0.0085
#> 15 Remmers et al. 1949 37 0.49 0.5361 0.0294
#> 16 Sullivan & Skanes 1974 14 0.51 0.5627 0.0909
#> 17 Sullivan & Skanes 1974 40 0.40 0.4236 0.0270
#> 18 Sullivan & Skanes 1974 16 0.34 0.3541 0.0769
#> 19 Sullivan & Skanes 1974 14 0.42 0.4477 0.0909
#> 20 Wherry 1952 20 0.16 0.1614 0.0588
#>
# fit random-effects model
res <- rma(yi, vi, data=dat, method="ML", digits=3)
res
#>
#> Random-Effects Model (k = 20; tau^2 estimator: ML)
#>
#> tau^2 (estimated amount of total heterogeneity): 0.001 (SE = 0.009)
#> tau (square root of estimated tau^2 value): 0.034
#> I^2 (total heterogeneity / total variability): 2.86%
#> H^2 (total variability / sampling variability): 1.03
#>
#> Test for Heterogeneity:
#> Q(df = 19) = 20.974, p-val = 0.338
#>
#> Model Results:
#>
#> estimate se zval pval ci.lb ci.ub
#> 0.380 0.045 8.505 <.001 0.292 0.468 ***
#>
#> ---
#> Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#>
# predicted average correlation (with 95% CI)
predict(res, transf=transf.ztor)
#>
#> pred ci.lb ci.ub pi.lb pi.ub
#> 0.363 0.284 0.436 0.263 0.455
#>
# funnel plot
funnel(res, ylim=c(0,0.4))
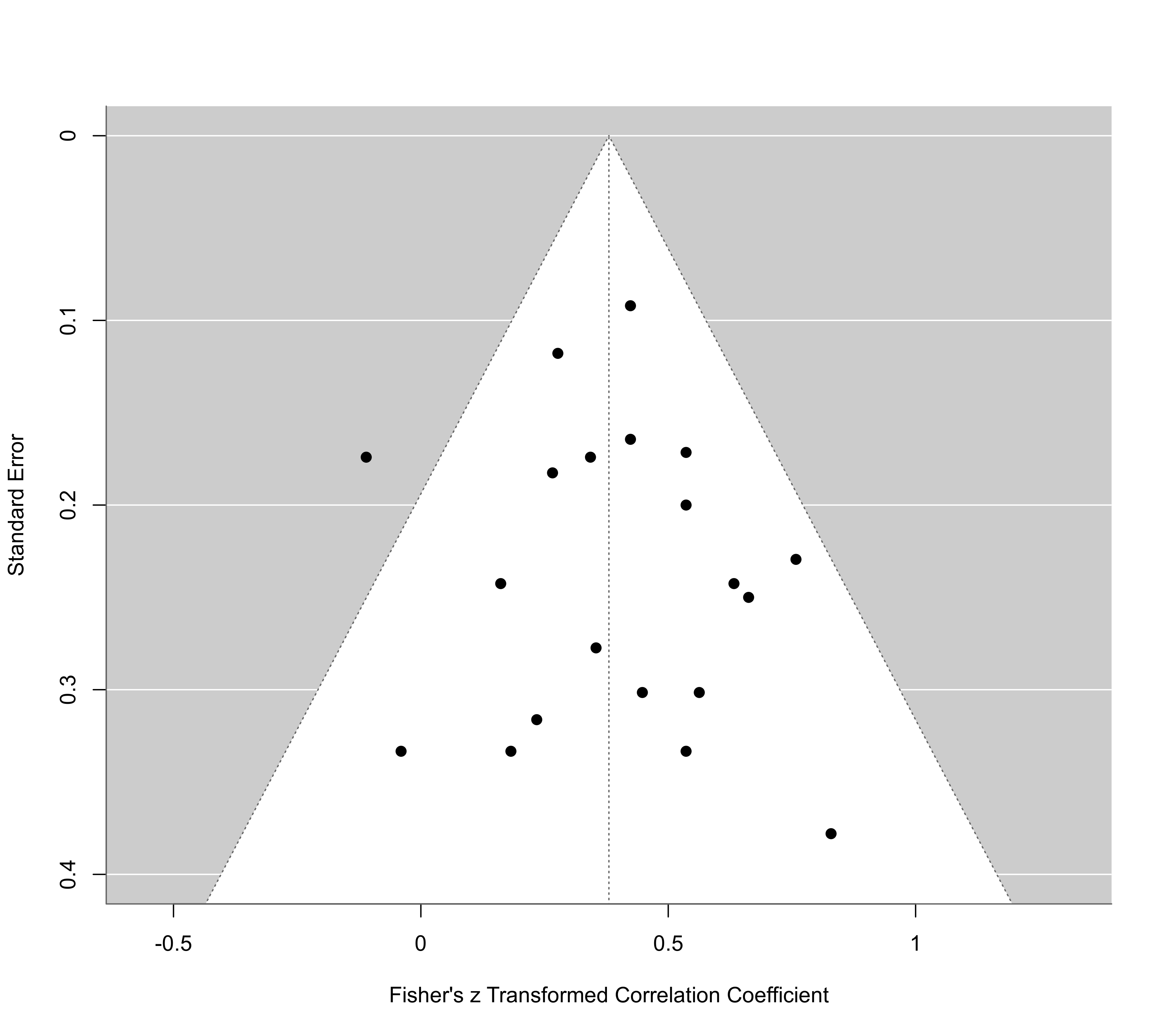 # selection functions from Vevea & Woods (2005)
tab <- data.frame(
steps = c(0.005, 0.01, 0.05, 0.10, 0.25, 0.35, 0.50, 0.65, 0.75, 0.90, 0.95, 0.99, 0.995, 1),
delta.mod.1 = c(1, 0.99, 0.95, 0.80, 0.75, 0.65, 0.60, 0.55, 0.50, 0.50, 0.50, 0.50, 0.50, 0.50),
delta.sev.1 = c(1, 0.99, 0.90, 0.75, 0.60, 0.50, 0.40, 0.35, 0.30, 0.25, 0.10, 0.10, 0.10, 0.10),
delta.mod.2 = c(1, 0.99, 0.95, 0.90, 0.80, 0.75, 0.60, 0.60, 0.75, 0.80, 0.90, 0.95, 0.99, 1.00),
delta.sev.2 = c(1, 0.99, 0.90, 0.75, 0.60, 0.50, 0.25, 0.25, 0.50, 0.60, 0.75, 0.90, 0.99, 1.00))
# apply step function model with a priori chosen selection weights
sel <- lapply(tab[-1], function(delta) selmodel(res, type="stepfun", steps=tab$steps, delta=delta))
# estimates (transformed correlation) and tau^2 values
sav <- data.frame(estimate = round(c(res$beta, sapply(sel, function(x) x$beta)), 2),
varcomp = round(c(res$tau2, sapply(sel, function(x) x$tau2)), 3))
sav
#> estimate varcomp
#> 0.38 0.001
#> delta.mod.1 0.35 0.005
#> delta.sev.1 0.32 0.010
#> delta.mod.2 0.36 0.003
#> delta.sev.2 0.33 0.006
############################################################################
# selection functions from Vevea & Woods (2005)
tab <- data.frame(
steps = c(0.005, 0.01, 0.05, 0.10, 0.25, 0.35, 0.50, 0.65, 0.75, 0.90, 0.95, 0.99, 0.995, 1),
delta.mod.1 = c(1, 0.99, 0.95, 0.80, 0.75, 0.65, 0.60, 0.55, 0.50, 0.50, 0.50, 0.50, 0.50, 0.50),
delta.sev.1 = c(1, 0.99, 0.90, 0.75, 0.60, 0.50, 0.40, 0.35, 0.30, 0.25, 0.10, 0.10, 0.10, 0.10),
delta.mod.2 = c(1, 0.99, 0.95, 0.90, 0.80, 0.75, 0.60, 0.60, 0.75, 0.80, 0.90, 0.95, 0.99, 1.00),
delta.sev.2 = c(1, 0.99, 0.90, 0.75, 0.60, 0.50, 0.25, 0.25, 0.50, 0.60, 0.75, 0.90, 0.99, 1.00))
# apply step function model with a priori chosen selection weights
sel <- lapply(tab[-1], function(delta) selmodel(res, type="stepfun", steps=tab$steps, delta=delta))
# estimates (transformed correlation) and tau^2 values
sav <- data.frame(estimate = round(c(res$beta, sapply(sel, function(x) x$beta)), 2),
varcomp = round(c(res$tau2, sapply(sel, function(x) x$tau2)), 3))
sav
#> estimate varcomp
#> 0.38 0.001
#> delta.mod.1 0.35 0.005
#> delta.sev.1 0.32 0.010
#> delta.mod.2 0.36 0.003
#> delta.sev.2 0.33 0.006
############################################################################